

NLPiation #32 - Reasoning, Retrieval, Representation
Advances in model reasoning, multi-modal retrieval, embedding geometry, and conversational coherence.

Welcome to my natural language processing newsletter, where I keep you up-to-date on the latest research papers, practical applications, and useful libraries. I aim to provide valuable insights and resources to help you stay informed and enhance your NLP skills. Let’s get to it!
Reasoning Models to the Rescue
📝 Leveraging Reasoning Model Answers to Enhance Non-Reasoning Model Capability [paper]

Test-time scaling is a powerful approach to improve the LLMs capabilities, but it needs more resources (GPU) and increases latency. This paper offers an alternative. They propose using high-quality outputs from reasoning language models to improve less computationally demanding, non-reasoning models. They performed 3 experiments to supervise fine-tune Qwen2.5-32B using a diverse dataset (~1.3M) from domains like Mathematics, code, Q&A,...
Different techniques were used to select ground truth for tuning the model:
1) Original target response from the curated dataset,
2) Only the final answer of the reasoning model (R1) output, and
3) Summarizing the thinking process and prepending it to the final answer.
It was found that the choice of target selection method significantly impacts the resulting model's strengths and weaknesses across different tasks. For example, using direct answers from reasoning models showed substantial improvements in reasoning and coding. Like ~10% increase on HumanEval and GSM8K. While underperforming on chat-oriented benchmarks. Alternatively, the think summarization approach achieved the highest GPQA score (47.7%). This method could result in smaller, more efficient models by leveraging reasoning models.
Multi-Modal RAG
📝 UniversalRAG: Retrieval-Augmented Generation over Corpora of Diverse Modalities and Granularities [paper] [blog] [code]
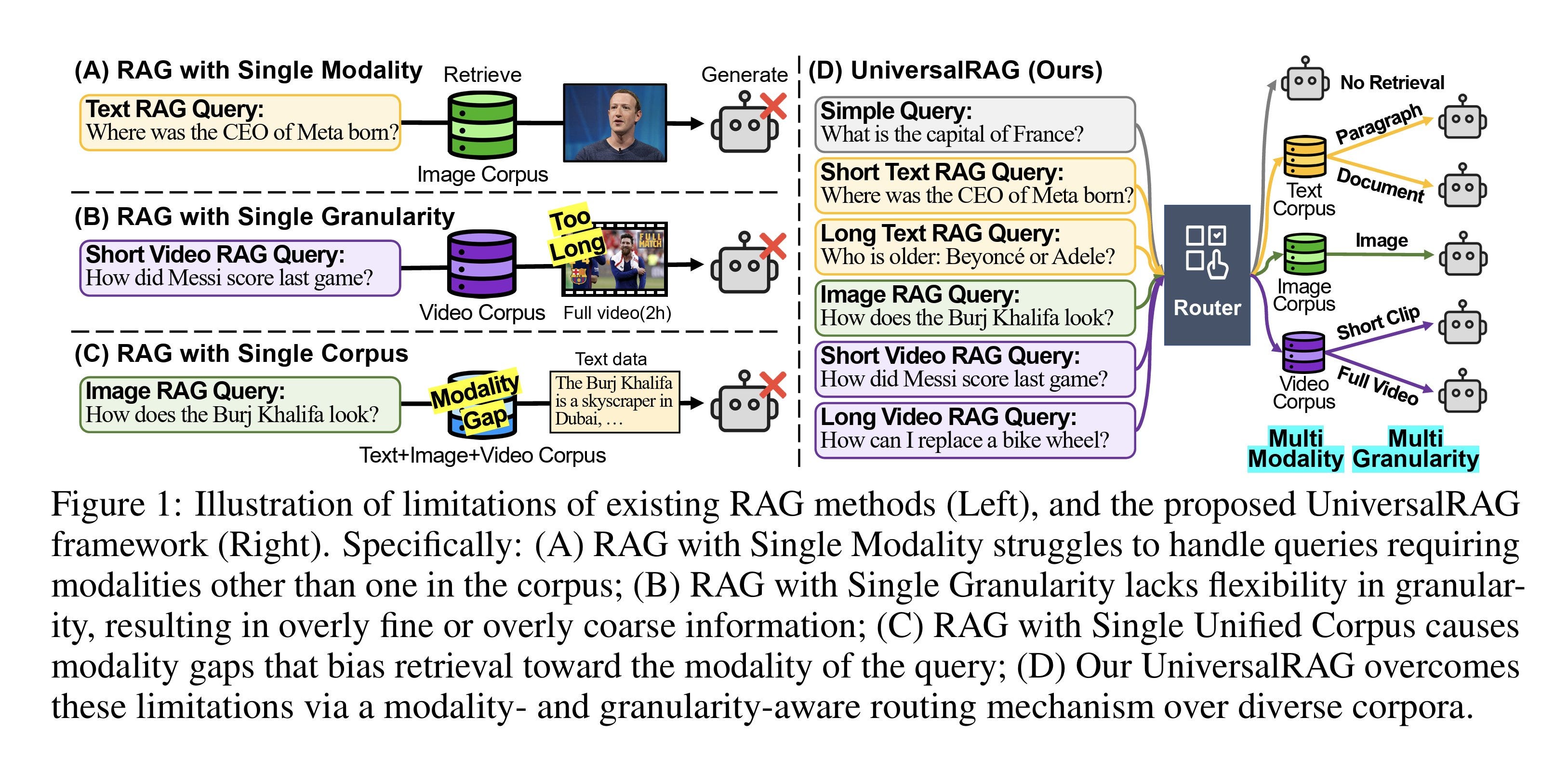
Most RAG systems today are constrained to single modalities (mostly text) or treat all content in a unified embedding space, which leads to problems like "modality gaps". The modality gap happens when different modalities are mapped into a shared embedding space, but the model clusters them just by data type. Even if a text and an image are about the same topic, the model still keeps them far apart because one is text and one is an image.
For example, if the question is "How does the Eiffel Tower look?", it is best to retrieve an image of the tower to answer the question, rather than texts which describe the tower. UniversalRAG adapts dynamically to both the modality and granularity needed for a query. The authors developed a routing mechanism that identifies the most appropriate modality (text, image, video) and granularity (paragraph, document, clip, video) for each query. Either training-free (using GPT-4o) or training-based (using models like DistilBERT and T5).
UniversalRAG outperforms existing RAG methods by accurately routing queries to the most relevant modality and granularity. This leads to higher accuracy and efficiency across eight benchmarks, with significant gains in tasks like HotpotQA and LVBench. It also generalizes well: trained routers excel in familiar domains, while a training-free GPT-4o router handles unseen queries better. An ensemble approach combines their strengths, making UniversalRAG both effective and robust.
Reverse Engineering Embedding Vectors
📝 Harnessing the Universal Geometry of Embeddings [paper]
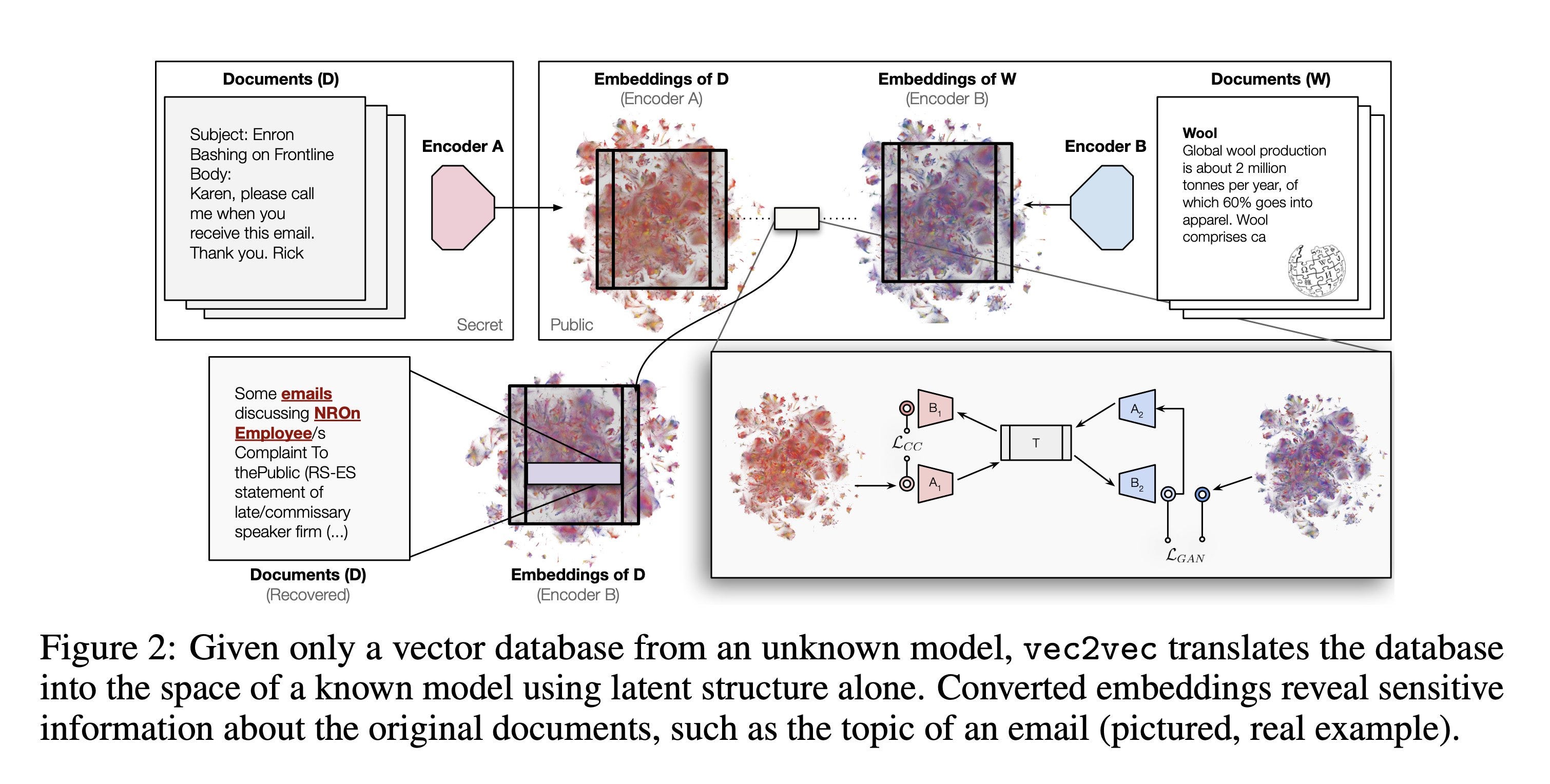
Your vector databases might not be as safe as you think! This paper demonstrated that embeddings from different models can be translated into one another’s vector space without supervision, which has serious complications.
The authors suggest that a universal latent space exists across different embedding models, meaning neural networks trained on similar tasks learn representations that can be aligned geometrically, even without access to the original inputs or models. Without going too deep into the details, their system does not require original texts, an original model, or paired examples. They want to convert vectors from Model A’s space into Model B’s space, such that the converted vectors mean the same thing.
vec2vec learns to translate embeddings from one model to another by mapping them into a shared “universal” space and then reconstructing them in the target model’s format. Uses adversarial training and consistency checks to preserve the meaning and structure of the original. It means embeddings alone can leak sensitive information, making vector databases insecure even without access to the original text. This work shows that different models share a universal structure, enabling translations and interoperability across systems.
It also gives strong evidence that neural models trained on similar tasks learn converging internal representations. Read the paper for details on how the adapters, shared backbone, and adversarial training were done.
Multi-Trun Evaluation
📝 LLMs Get Lost In Multi-Turn Conversation [paper] [code] [dataset]
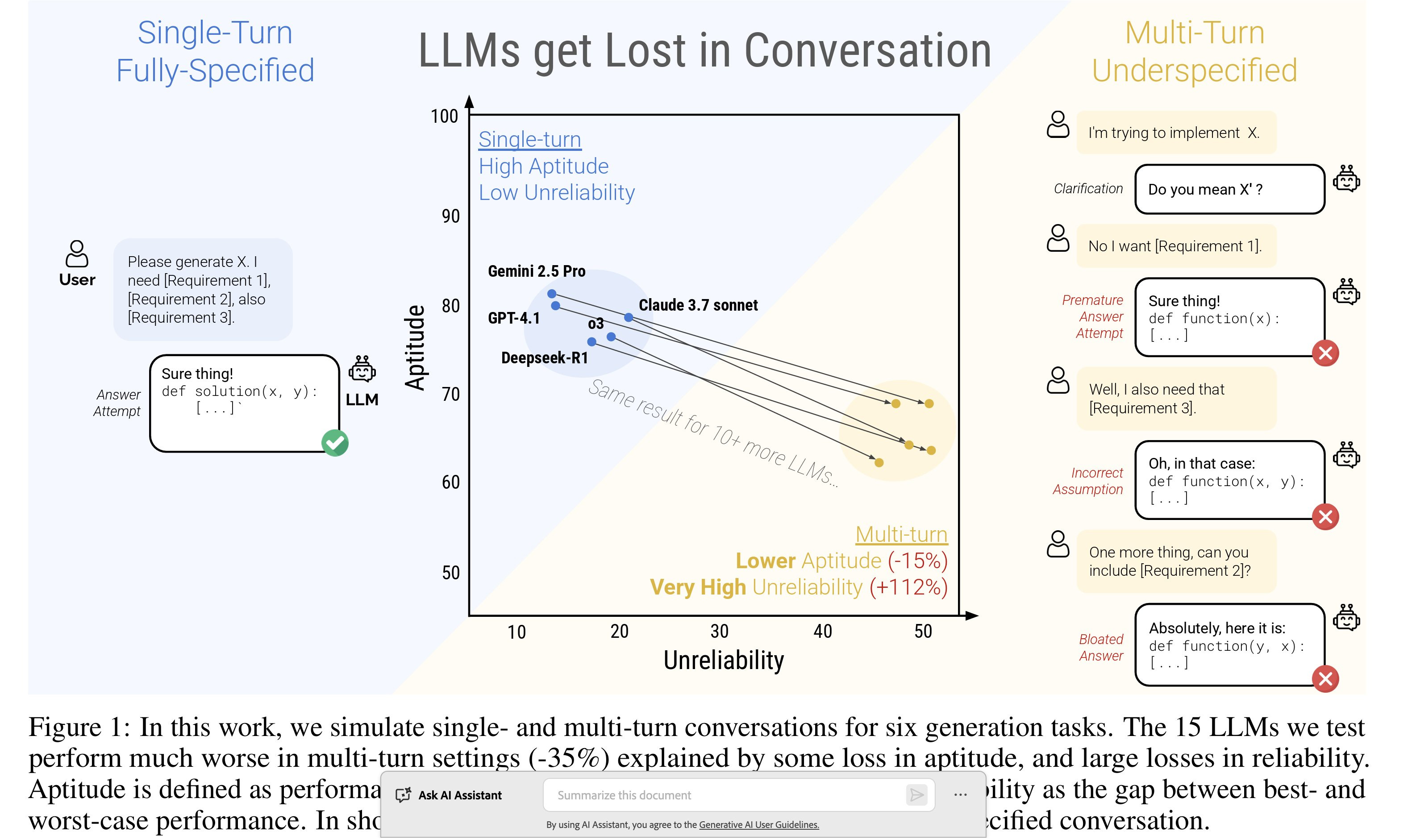
Most LLM benchmarks use ideal, single-turn prompts, but real users give vague, multi-turn instructions. This study shows LLMs perform much worse in these realistic settings, highlighting flaws in current evaluation methods.
The authors simulate both single-turn and multi-turn scenarios to quantify how performance drops when instructions are given piece by piece. Two metrics, aptitude and unreliability used to back their arguments that LLMs “get lost” in multi-turn, underspecified conversations. Aptitude is the model’s best-case performance (90th percentile), while unreliability is the gap between best and worst cases (90th–10th percentile) across runs on the same task.
The results showed that LLMs tend to:
1) Make premature assumptions,
2) Attempt final answers too early,
3) Fail to recover from earlier mistakes, and
4) Over-rely on their own past responses.
This results in performance dropped an average of 39% in multi-turn settings.
The degradation is due to a minor loss in aptitude (about 15–16%), and a massive increase in unreliability (over 112% on average). Even top-tier models (e.g., GPT-4.1, Gemini 2.5 Pro, Claude 3.7 Sonnet) were highly unreliable in multi-turn settings. LLMs that excel in idealized benchmarks may fail in the messy reality of human-like interaction. It calls for new evaluation standards and architectural improvements (restarting conversations or improving instructions to improve outcomes) to better handle multi-turn.
Final Words,
What do you think of this newsletter? I would like to hear your feedback.
What parts were interesting? What sections did you not like? What was missing, and do you want to see more of it in future?
Please reach out to me at nlpiation@gmail.com.