

NLPiation #31 - Attention, Reasoning, Retry
Exploring new frontiers in coding, comprehension, and the art of trying again.

Welcome to my natural language processing newsletter, where I keep you up-to-date on the latest research papers, practical applications, and useful libraries. I aim to provide valuable insights and resources to help you stay informed and enhance your NLP skills. Let’s get to it!
Group Attention
📝 Multi-Token Attention [paper]
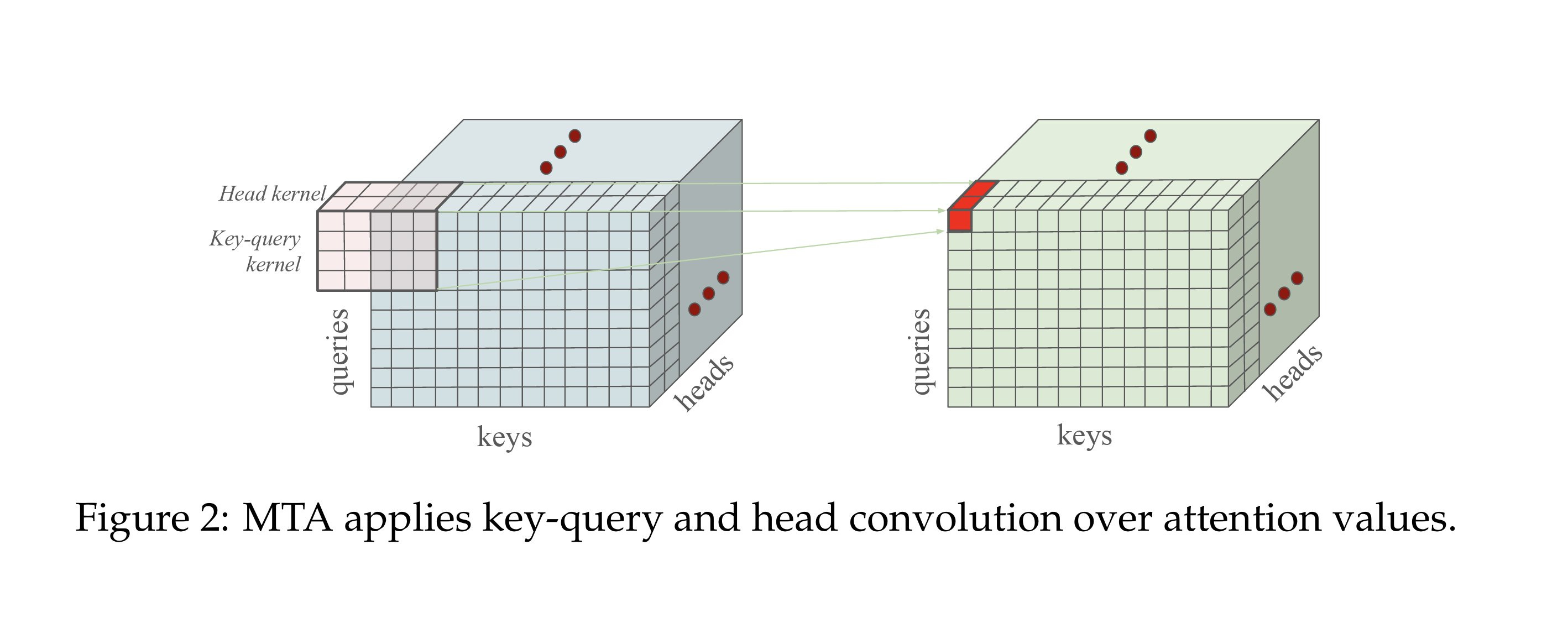
In traditional LLM attention, each weight only considers how one query vector matches with one key vector. This makes it hard for the model to find important information that requires looking at groups of tokens together.
The researchers at Meta propose MTA (Multi-Token Attention) which allows models to condition attention weights on multiple query and key vectors simultaneously. It is done by performing a convolution on top of the key-query vectors, and across the heads. The key-query convolution over the attention weights allows the model to capture nearby tokens that influence each other, while the head mixing convolution shares information across attention heads to amplify important signals. Then, normalization to improve gradient flow.
The key-query convolution combines information from nearby words by applying a 2D filter to the attention scores matrix. In experiments, it examines up to 6 previous positions in the query dimension and a window of 11 positions around the current location in the key dimension. The head mixing convolution groups the heads, and applies a convolution in each group, which allows the heads to share information. The proposed changes improved the model's accuracy, especially for long-context tasks, while adding only 0.001% more parameters.
It perfectly solves letter block identification tests (toy task) where standard Transformers fail, while reducing perplexity in language modeling and dramatically improving Needle-in-a-Haystack accuracy, especially with multiple deeply embedded needles.
Deep Coder
📝 DeepCoder: A Fully Open-Source 14B Coder at O3-mini Level [Report] [Code]
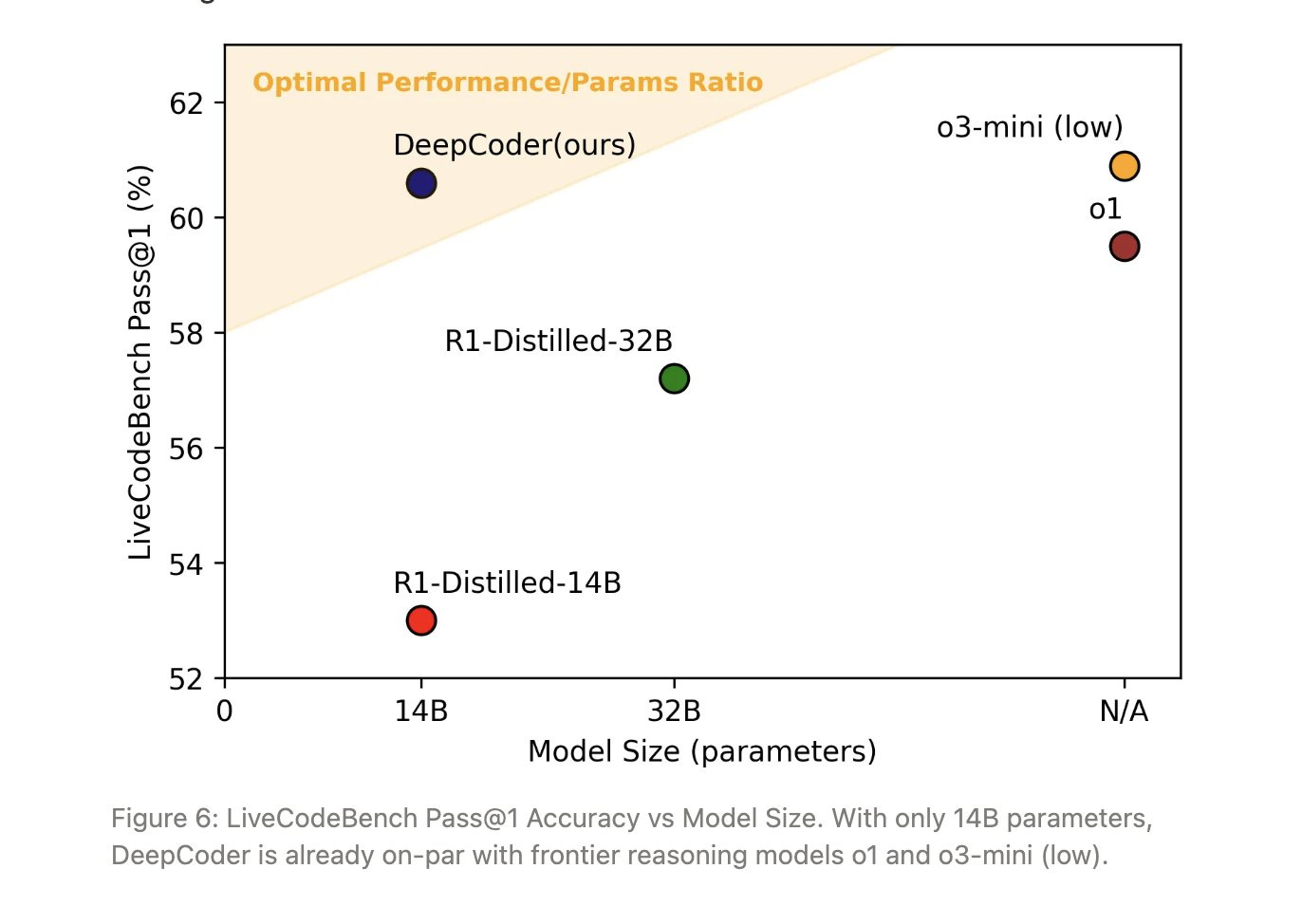
DeepCoder-14B-Preview is a code reasoning model that achieves impressive performance compared to much larger models using reinforcement learning. The authors have open-sourced their code, dataset, logs, ...
The first challenge was lack of a quality dataset. They addressed this by curating a training set of 24K verifiable coding problems and implementing filtering methods, including programmatic verification, test-based filtering (≥5 unit tests per problem), and deduplication. They used the GRPO+ optimization which has the following improvements: No entropy loss, no KL loss, clip high (to encourage exploration and stabilize entropy), and overlong filtering (to preserve long-context reasoning)
The overlong filtering identifies sequences that have been truncated because they exceeded the current context length limit, and "masks out" these truncated parts from the loss function calculation. So, the model can think longer without getting penalize. They used Outcome Reward Model (ORM) reward that assigns a binary reward of 1 only when the generated code passes all sampled unit tests, and 0 if the code fails on any test case or is formatted incorrectly. No partial rewards are given to avoid reward hacking.
The paper also mentions details about their sanbox environment to test the model outputs, iterative context lengthening technique, system optimizations, and more. I recommend taking the time to read the paper. DeepCoder-14B-Preview matched OpenAI's o3-mini on LiveCodeBench (60.6%) and Codeforces (1936 rating) with only 14B parameters. It also generalized well to math problems, scoring 73.8% on AIME2024 despite being trained solely on coding.
Opinion: It might be interesting to read the discussion in Reddit where a user compared DeepCoder 14B vs Qwen2.5 Coder 32B vs QwQ 32B. They prompted the models (same hyperparameters) to generate the code for a bouncing ball in a hexagon demo. Their conclusion was that the "Qwen2.5 Coder 32B" is still the better choice for coding. Also, there are some great notes in the comments like the idea of using a 5-shot prompt instead of one-shot to help the smaller models, or the fact that a user reported the "QwQ-32" model was also able to accomplish the task with "correct" parameters.... [Reddit Post]
Improve Reasoning
📝 Leveraging Reasoning Model Answers to Enhance Non-Reasoning Model Capability [paper]

Test-time scaling is a powerful approach to improve the LLMs capabilities, but it needs more resources (GPU) and increases latency. This paper offers an alternative. They propose using high-quality outputs from reasoning language models to improve less computationally demanding, non-reasoning models. They performed 3 experiments to supervise fine-tune Qwen2.5-32B using a diverse dataset (~1.3M) from domains like Mathematics, code, Q&A,...
Different techniques were used to select ground truth for tuning the model: 1) Original target response from the curated dataset, 2) Only the final answer of the reasoning model (R1) output, and 3) Summarizing the thinking process and prepending it to the final answer. It was found that the choice of target selection method significantly impacts the resulting model's strengths and weaknesses across different tasks. For example, using direct answers from reasoning models showed substantial improvements on reasoning and coding.
Like ~10% increase on HumanEval and GSM8K. While underperforming on chat-oriented benchmarks. Alternatively, the think summarization approach achieved the highest GPQA score (47.7%). This method could result in smaller, more efficient models by leveraging reasoning models.
Try Again
📝 ReZero: Enhancing LLM search ability by trying one-more-time [paper] [Model]
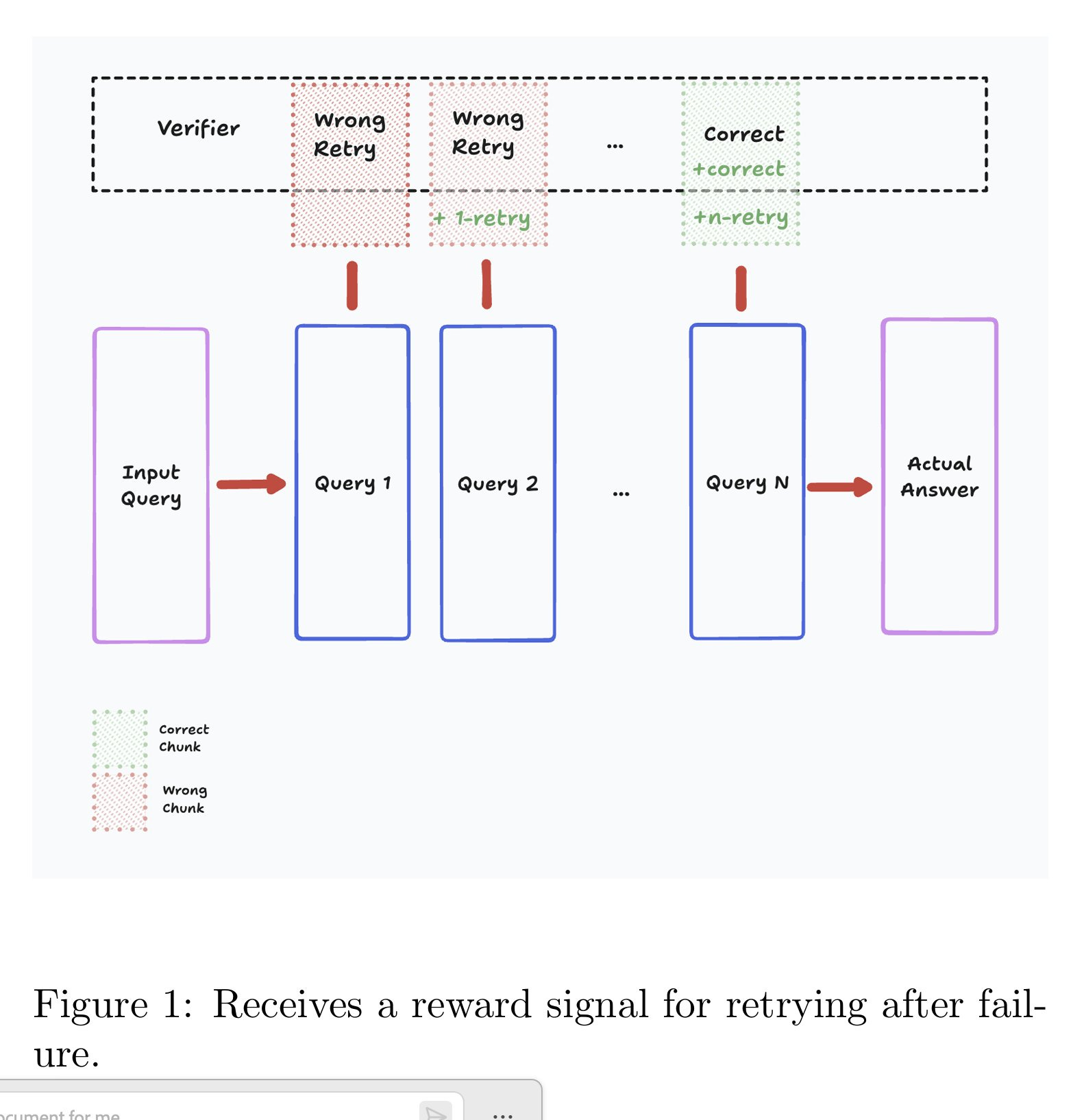
Current RAG typically focus on improving query formulation or reasoning over retrieved documents, but don't specifically encourage persistence after failed searches. ReZero addresses this gap...
Retry-Zero is a RL framework that rewards LLMs for attempting additional search queries after an initial unsuccessful search attempt. It encourages persistence, mirroring the human problem-solving strategy of "if at first you don't succeed, try again." They fine-tuned Llama3.2-3B-Instruct using Group Relative Policy Optimization (GRPO) with multiple reward functions: correctness, format, chunk retrieval, and more importantly a "retry" reward that specifically incentivizes the model to attempt additional searches.
The LLM operates in a search environment where it can generate search queries, process retrieved information, think internally, provide final answers, and crucially, issue follow-up search queries sequentially. The training loop potentially use multiple search-retrieval. After each loop the rewards are calculated based on answer correctness, format adherence, information retrieval quality, and persistence in searching, leading to policy updates that optimize the model's information-seeking behavior.
ReZero achieved 46.88% accuracy compared to only 25% for the baseline model. The approach notably improved performance on complex information-seeking tasks where initial queries often prove insufficient.
Final Words,
What do you think of this newsletter? I would like to hear your feedback.
What parts were interesting? What sections did you not like? What was missing, and do you want to see more of it in future?
Please reach out to me at nlpiation@gmail.com.