

NLPiation #30 - Decomposition, Diffusion, Control
Exploring decomposition, diffusion, and control beyond traditional agents in NLP.

Welcome to my natural language processing newsletter, where I keep you up-to-date on the latest research papers, practical applications, and useful libraries. I aim to provide valuable insights and resources to help you stay informed and enhance your NLP skills. Let’s get to it!
Self-Improving LLMs
📝 LADDER: Self-Improving LLMs Through Recursive Problem Decomposition [paper]

This paper introduces LADDER, a framework that enables LLMs to improve their problem-solving capabilities autonomously through self-guided learning. It is a novel approach where LLMs recursively generate and solve progressively simpler variants of complex problems, creating their learning path without human supervision. However, the framework requires a reliable verification mechanism to verify the answers.
Also, TTRL enables models to learn on the spot by generating simpler variants of hard problems and applying RL to develop problem-specific expertise. This approach provides an effective way to scale test-time compute, with the model returning to its original weight after.
This method improved small models' performance, boosting Llama 3B from 1% to 82% accuracy and enabling a 7B parameter model to achieve 90% on the MIT Integration Bee with TTRL. This outperformed much larger models like OpenAI's o1. The authors state that this approach could work in any domain that has:
Way to generate problem variants
"generator-verifier" where verifying solutions is easier than generating them
A reliable verification tool or system
Like Competitive Programming or Mathematics.
Diffusion LLMs
📝 Large Language Diffusion Models [paper] [blog] [code] [model]
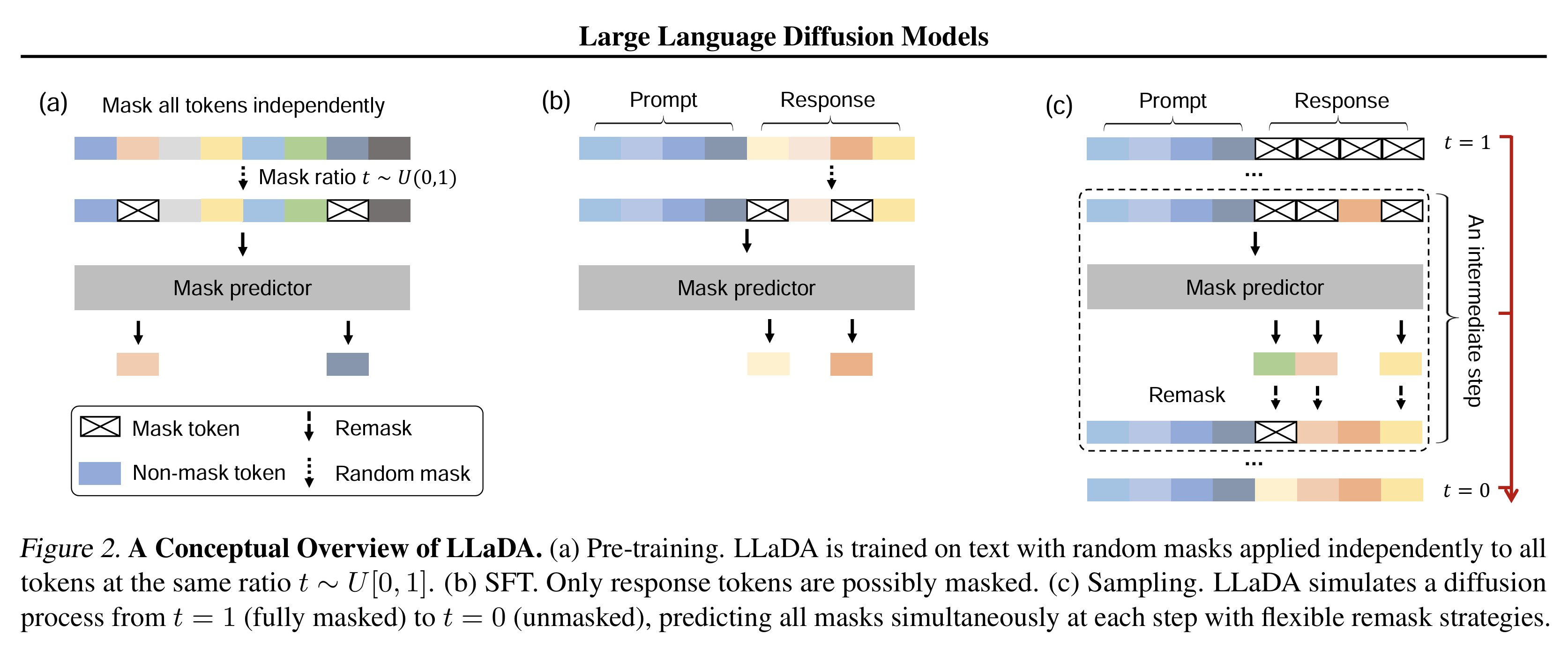
This paper presents the diffusion modelling approach to replace the well-known autoregressive model that predicts words one token at a time, from left to right. It's been a proven image/video processing technique, but with no success for text.
This paper's core concept centers on the fundamental property of diffusion models, which begin with a noise-filled sample and gradually eliminate noise through iterative steps. They trained a vanilla transformer (8B size) by predicting randomly masked tokens on 2.3T tokens.
It demonstrated exceptional scalability to 10²³ FLOPs, superior in-context learning versus LLaMA models, solved the "reversal curse," achieved 70.7% accuracy on GSM8K math tasks, and maintained coherent multi-turn dialogues across languages. LLaDA begins with fully masked sequences and generates text through gradual unmasking. It employs parallel token prediction alongside strategic remasking techniques (masking generated tokens for the next iteration) to optimize the diffusion process.
Random remasking randomly remasks a percentage of tokens at each step. Low-confidence remasking prioritizes tokens with the lowest prediction confidence. Semi-autoregressive remasking divides sequences into blocks, generating them left-to-right. These models are faster during text generation, and we already have examples of commercial-grade dLLMs being released, which look very promising. [Demonstration tweet]
Improve Agents
📝 Agents Are Not Enough [paper]
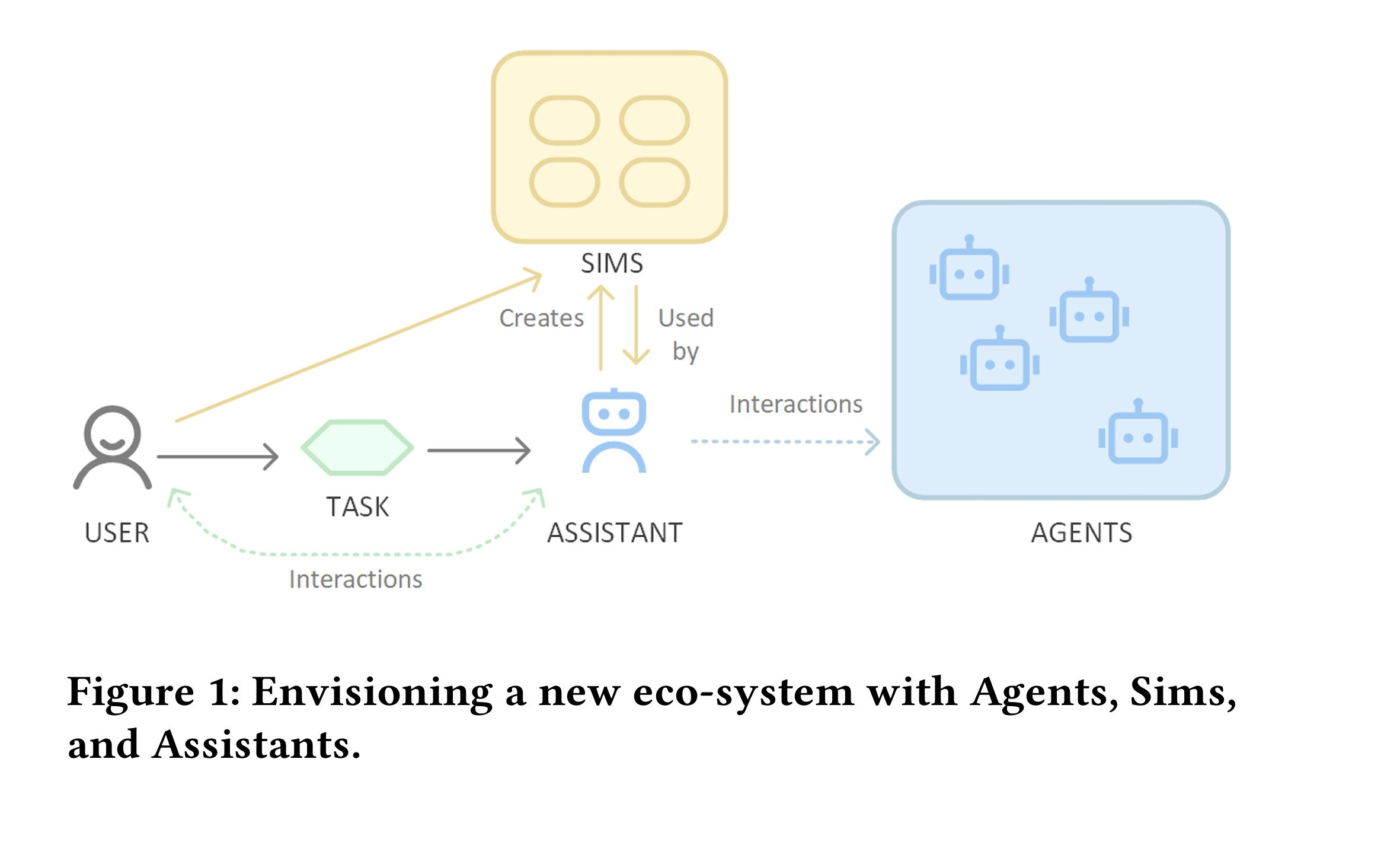
This paper looks at the history of AI agents (from early AI agents to cognitive architectures) and explores the limitations of the current technology and proposes a new ecosystem approach to make them more effective. They identified limitations as poor generalization, scalability problems, coordination failures, robustness, and ethical concerns. These technical shortcomings explain why agents remain limited in practical applications despite advances in underlying AI technologies.
They hypothesize AI agents cannot succeed alone because they lack the broader ecosystem needed for personalization, trust, and social acceptance. The paper proposes integrating Agents with Sims and Assistants to create value while adapting to user-specific contexts. The ecosystem comprises Agents (specialized task modules), Sims (personalized user representations), and Assistants (user-facing coordinators). This framework addresses the limitations of agents alone by integrating privacy, personalization, and trust in one system.
This conceptual framework for future agent development emphasizes the interconnection between Agents, Sims, and Assistants, comparable to how app stores standardized software distribution.
Length Control
📝 Precise Length Control in Large Language Models [paper]

Currently, even with direct instructions, limiting LLM response length remains challenging. This research explores the idea of controlling the LLM response length without compromising response quality. It's done by incorporating a "length-difference positional encoding" (LDPE) as a countdown mechanism, allowing the model to know exactly how many tokens remain before it should terminate its response. It adds a secondary positional encoding to the input embeddings.
The LDPE applies the countdown to the entire prompt-response pair; the other approach, ORPE (Offset Reverse Positional Encoding), only applies the countdown to the model's response portion. Both these techniques are tested by fine-tuning Mistral-7B and LLaMA3-8B. In summarization tasks, their method achieved great control (mean errors of 2.4-2.8 tokens) compared to prompt-based length control (mean error of 24.8 tokens). Also, they showed that response quality (measured by BERT scores) remained consistent across different lengths.
They also developed "Max New Tokens++" as an extension that enables flexible upper-bound length control rather than exact targets. It helps the models to do content-aware termination, instead of the usual max_token argument that simply cuts off generation.
Opinion: This paper really caught my interest because during my PhD, I spent a lot of time working on beam search extensions to control how long a model's responses would be. I tried using different penalty functions to make it work, but nothing I tried succeeded. I decided back then that trying to control response length after a model is already trained is really difficult. It would probably be much simpler to teach the model this skill during the training or fine-tuning process instead.
Final Words,
What do you think of this newsletter? I would like to hear your feedback.
What parts were interesting? What sections did you not like? What was missing, and do you want to see more of it in future?
Please reach out to me at nlpiation@gmail.com.