

NLPiation #29 - From Thinking to Scaling
Exploring efficient reasoning, context extraction, and model scaling innovations in today's cutting-edge NLP research.

Welcome to my natural language processing newsletter, where I keep you up-to-date on the latest research papers, practical applications, and useful libraries. I aim to provide valuable insights and resources to help you stay informed and enhance your NLP skills. Let’s get to it!
Test-Time Scaling
📝 s1: Simple test-time scaling [paper]

Test-time scaling is a fairly effective method that forces LLMs to think (provide reasoning steps) before providing the final answer. This research dives into data curation and controlling the thinking process. The first takeaway of this paper is curating the 1K dataset with questions and reasoning traces filtered by:
1) difficulty: Where two models (Qwen 7/32) generate answers, with Claude Sonet acting as a judge, and the sample is selected only if both models get the answer wrong.
2) Diversity/Quality: Remove samples with a formatting issue and uniformly select samples from multiple clusters. (Math, AGIEval, OlympicArena,...) The preference is for samples with longer reasoning traces that translate to more difficult questions.
The next step is to control the reasoning budget by appending "Final Answer:" when the maximum thinking tokens are used to force the model to answer the question, or "Wait" token if it hasn't used the minimum required thinking tokens. It leads to double-checking the answer. They fine-tuned the Qwen 2.5-32B-Instruct resulting in a very sample-efficient S1 model. It outperforms QwQ and O1 models with only a 1K dataset. size. The model took only 26 minutes to train using 16 H100 GPUs.
400x Faster Embedding
📝 Train 400x faster Static Embedding Models with Sentence Transformers [Post]

I came across a post from Hugging Face introducing a few new embedding models that are incredibly fast while maintaining much of the capability of popular models. The approach (from the Sentence Transformer library) is to train a static model using a contrastive learning loss function. It pulls similar text embeddings closer together and pushes dissimilar text embeddings apart in the vector space.
The method is pretty similar to the older static models like GloVe and Word2Vec which are a lookup table of pre-calculated embeddings. So, there is no inference latency, and the operation is as fast as retrieving a key from a dictionary!
The resulting models are 100-400x faster than transformer-based models while retaining 85%+ of their performance. This speed comes from replacing complex attention mechanisms with simple lookup and averaging operations. This enables on-device, in-browser, and edge computing applications because of its speed and efficiency. However, static models lack contextual understanding since they simply average token embeddings without considering surrounding words.
Still, the results look very promising and can be extremely useful in retrieval applications. They released two models for English Retrieval, and Multilingual Similarity tasks on the HF hub.
Enhance RAG
📝 LLMQuoter: Enhancing RAG Capabilities Through Efficient Quote Extraction From Large Contexts [paper]
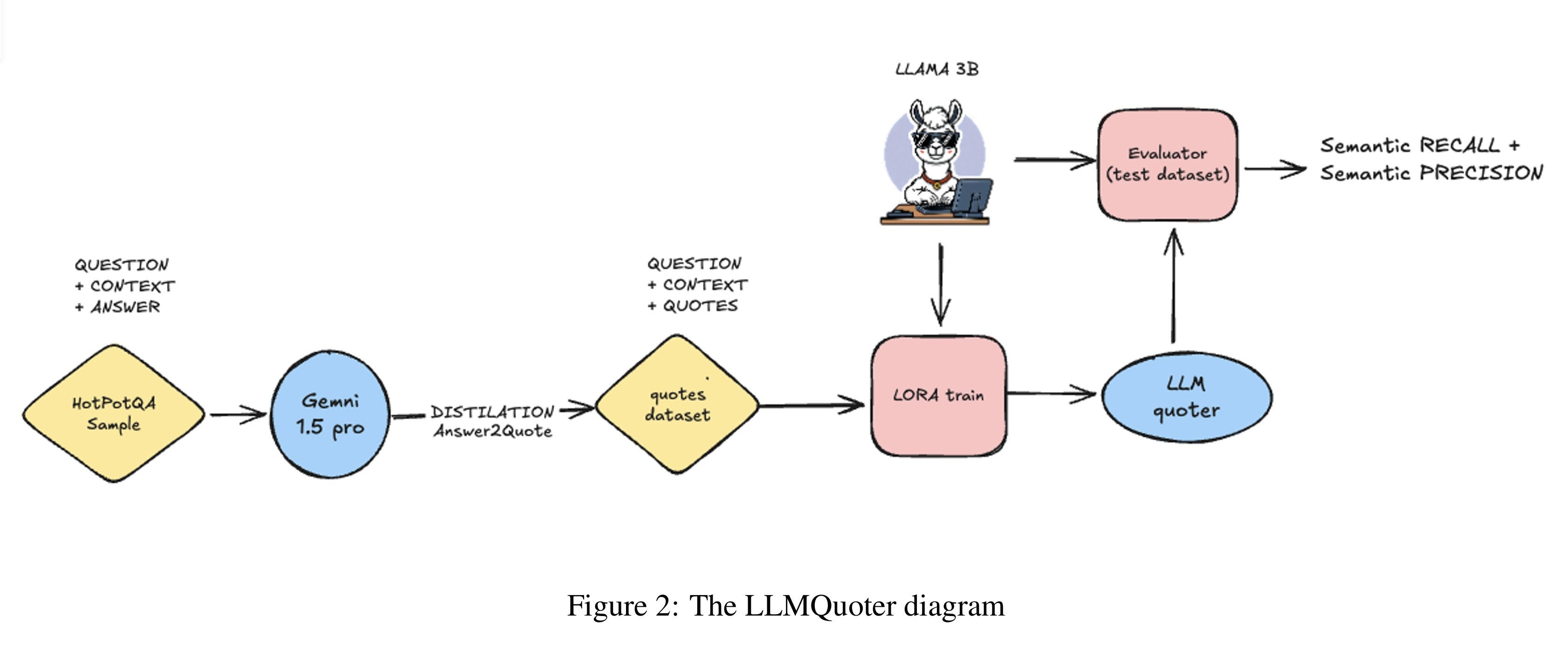
LLMQuoter improves RAG by breaking down the process into two steps: extracting relevant quotes from large contexts, and using those quotes for reasoning/answering questions. RAG pipelines typically have problems with effective reasoning based on long context. So, this paper proposes the idea of a "quote-first-then-answer" strategy instead of trying to reason over the full context.
It offers a distillation process where a larger model (Gemini-pro) acts as a teacher to extract quotes from long texts and fine-tune LLaMA-3B using LoRA to create the LLMQouter model, which basically is a quote extraction model based on the user's query. During the inference process, the LLMQuoter will feed its output the reasoning model alongside the asked question so the model can effectively reason in a shorter context. It enables each model to specialize on one task only: quote extraction and one for reasoning.
When tested across different models, the quote-first approach dramatically improved performance, with gains ranging from 12.7% for GPT-3.5 Turbo to an impressive 37.8% boost for LLAMA-1B, and 25.3% for LLAMA-3B.
Think Less?
📝 Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs [paper]
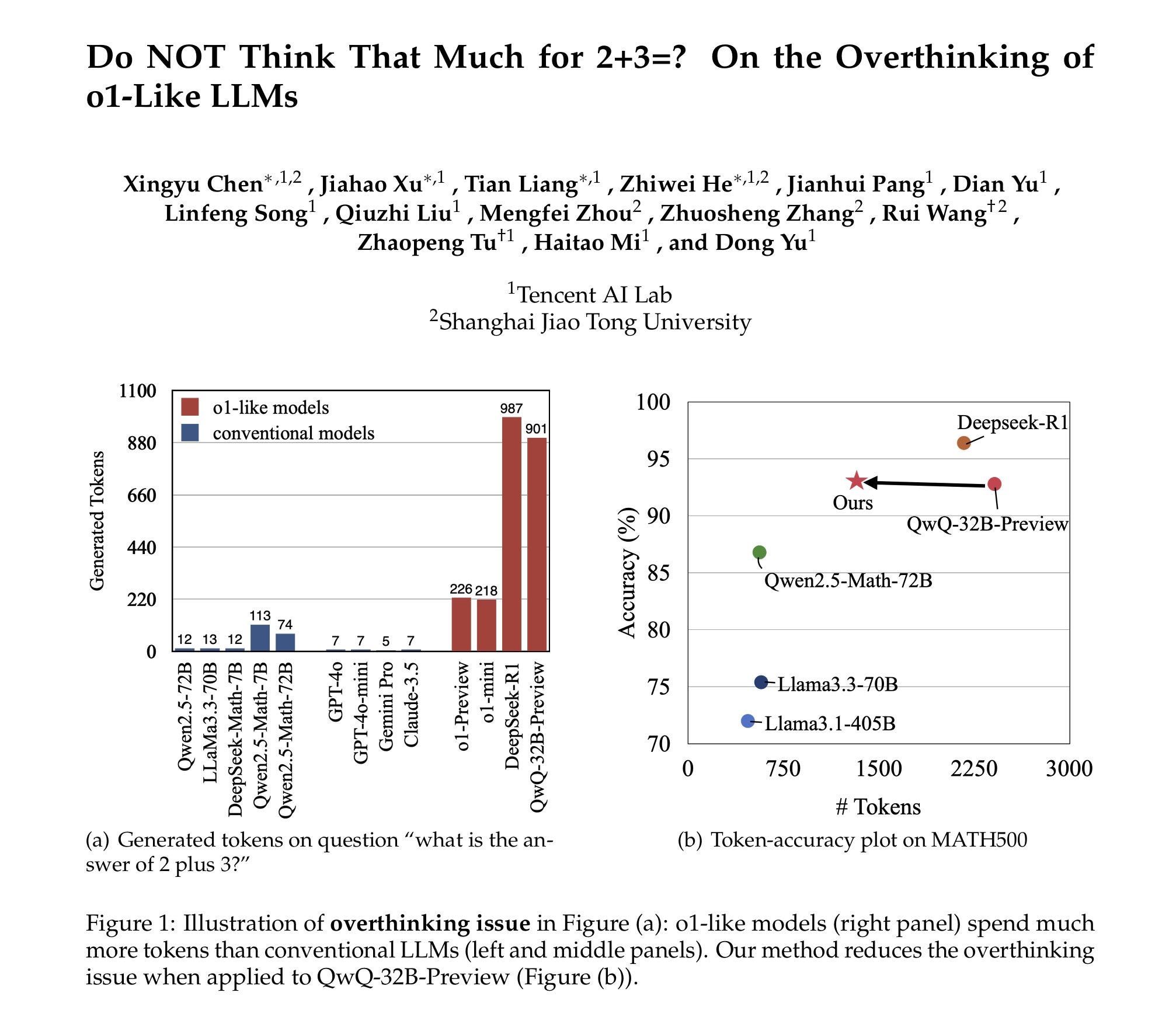
This paper studies the overthinking problem in LLMs, which causes the model to use a longer (1,953% more) Chain-of-Thought reasoning step on simple queries like "2+3" than regular models.
Their analysis shows the o1-like reasoning model often generates unnecessary solution rounds. They introduced two efficiency metrics. 1) Outcome Efficiency: How well later solutions improve accuracy., and 2) Process Efficiency: Evaluate the novelty/diversity of reasonings. It was shown that in over 92% of cases, the correct answer is found in the first solution round. In contrast, the later solutions often repeat earlier reasoning strategies without adding new insights. So, they propose strategies to mitigate overthinking.
The final solution combines training the model with Simple Preference Optimization (an extension to DPO, like adaptive margin and length regularization) to generate shorter responses at the model level, using carefully curated samples. followed by applying the FCS+Reflection strategy to structure and select those responses. It keeps the first correct solution plus one more solution for verification. Balances efficiency with the need for double-checking.
The paper's approach significantly improved efficiency, reducing token output by up to 48.6% while maintaining accuracy across datasets. It establishes a foundation for optimizing AI resource use, proving that models can be more efficient without compromising reasoning.
Final Words,
What do you think of this newsletter? I would like to hear your feedback.
What parts were interesting? What sections did you not like? What was missing, and do you want to see more of it in future?
Please reach out to me at nlpiation@gmail.com.