

NLPiation #29 - Caching, Context, Concepts
Exploring how caching strategies, context length, uncertainty estimation, and conceptual representations are reshaping knowledge retrieval in language models.

Welcome to my natural language processing newsletter, where I keep you up-to-date on the latest research papers, practical applications, and useful libraries. I aim to provide valuable insights and resources to help you stay informed and enhance your NLP skills. Let’s get to it!
Large Concept Models
📝 Large Concept Models: Language Modeling in a Sentence Representation Space [paper] [code]
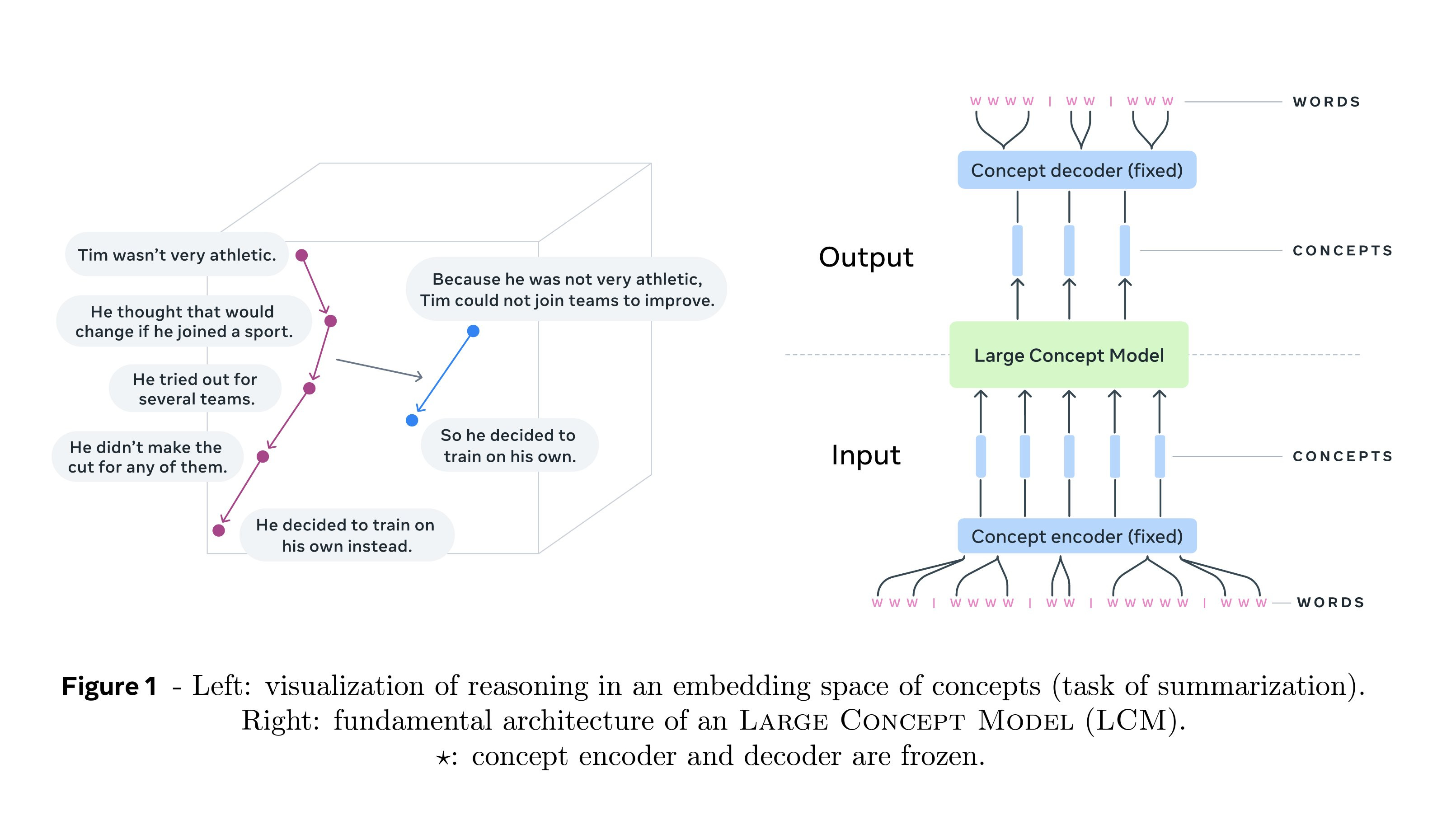
This paper introduces Large Concept Models (LCM) that process whole sentences at once (instead of tokens), like how humans naturally think in complete ideas rather than individual words. They used the encoder-decoder SONAR model as frozen components, with the LCM model in the middle. So, first, the LCM model receives the sentence embedding from the SONAR's encoder. Then, LCM generates the new embedding, which will be passed to SONAR's decoder for generation.
The selected architecture for LCM was named "Two-Tower," which consists of two components: contextualizer and denoiser, that are implemented using transformer layers. They experimented with different architectures, but Two-Tower proved to be more effective. This approach provides strong performance across languages (200 languages that SONAR supports) without specific training which is great for languages with low resources. LCM outperformed LLaMA-3.1 in the languages it supports.
Additionally, it is more efficient for long contexts as it operates on sentence-level rather than token-level while requiring no language-specific training and fine-tuning. The model offers a unique perspective to operate in an abstract semantic space (embedding) rather than with specific languages or modalities.
Uncertainty Estimation
📝 Rethinking Uncertainty Estimation in Natural Language Generation [paper]

This paper introduces a new approach to estimating uncertainty in Large Language Models (LLMs) called G-NLL (Greedy Negative log likelihood). Measuring uncertainty has many real-world applications that enable us to determine how confident the model is about its answer and, therefore, how trustworthy it is. It leads to improved safety, UX and quality control. It might even help with hallucination...

Current techniques analyze multiple outputs from the model, which is expensive and not very useful at scale! This paper proposes using the negative log-likelihood of the most likely output sequence, which is generated using the greedy decoding method. The paper has in-depth mathematical proofs, but the intuition is that if even the model's most likely output is very uncertain, then the answer might not be correct! This uncertainty can trigger user warnings or human expert review when needed.
In testing, G-NLL achieved higher accuracy (0.824 AUROC vs 0.775-0.795 for others) while using just one sequence generation versus 10+ for other methods. (more efficient) It maintained strong performance across different architectures, model sizes, and tasks. (more robust)
Context or RAG
📝 Long Context vs. RAG for LLMs: An Evaluation and Revisits [paper]

Many studies compare the effectiveness of using RAG to break down a text into chunks and select important parts of the document vs. loading the full document in the model's context and letting it find the info.
The question is, which one results in higher accuracy? Focusing on increasing the models' context length or using better retrieval algorithms? Answering this question will help us to use the best approach in real-world applications to get the best results! This study curated a dataset of 19K questions filtered to make sure they require external knowledge for answering. These questions cover a wide range of sources and types like yes/no, summarization, or fact-based questions, ...
Long Context (LC) performed better than RAG with 56.3% vs 49.0% correct answers, excelling with well-structured content like Wikipedia articles. RAG demonstrated its advantages when handling dialogue-based contexts and fragmented information. LC demonstrated superior performance on fact-based questions like who, where, and which, while RAG proved comparable on open-ended questions and outperformed LC on yes/no queries. This suggests each approach excels with different question types.
No to RAG
📝 Don’t Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks [paper]

Cache-Augmented Generation (CAG) is a new method that replaces the need for real-time retrieval in question-answering systems (chatbots) by leveraging long-context LLMs. This is a simple technique using a 3-step approach.
1) External Knowledge Preloading: They preprocess and load all relevant documents into the LLM's extended context window and precompute the attention's key-value (KV) cache by feeding the document through the LLM.
2) Inference: They use the precomputed cache to generate responses without needing real-time retrieval. The cache is saved in memory.
3) Cache Reset: They efficiently manage the KV cache across multiple inference sessions.
If we compare techniques with an example: The main difference between CAG and traditional RAG is that CAG reads a book once, takes detailed notes, and references them for future questions, whereas traditional RAG re-reads the book for every question. It brings efficiency by reducing response time while maintaining or improving answer quality, simplification by eliminating the complexity of managing separate retrieval systems, and is future-proof as it becomes increasingly viable with advancements in LLMs.
CAG achieved higher BERTScore in most scenarios and significantly faster generation times (e.g., for HotPotQA large dataset: 2.32s vs 94.34s) while maintaining performance even with increasing context size.
Final Words,
What do you think of this newsletter? I would like to hear your feedback.
What parts were interesting? What sections did you not like? What was missing, and do you want to see more of it in future?
Please reach out to me at nlpiation@gmail.com.