

NLPiation #28 - Reasoning, Judging, Evolving
How Language Models Learn to Think, Judge, and Scale: From Code Evaluation to Memory-Efficient Reasoning.

Welcome to my natural language processing newsletter, where I keep you up-to-date on the latest research papers, practical applications, and useful libraries. I aim to provide valuable insights and resources to help you stay informed and enhance your NLP skills. Let’s get to it!
Judge Code
📝 CodeJudge-Eval: Can Large Language Models be Good Judges in Code Understanding? [paper] [code]
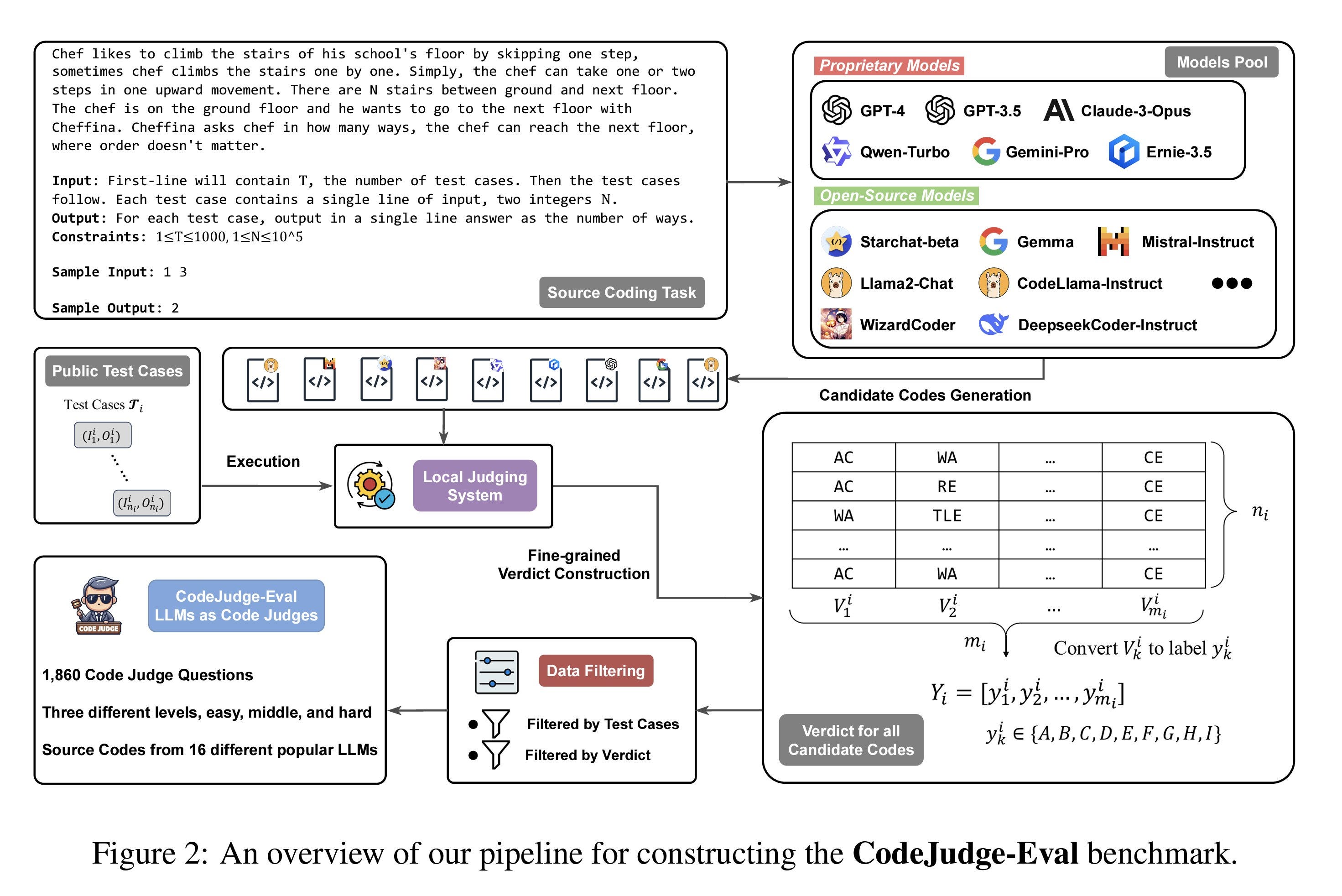
The paper introduces a new coding benchmark (CJ-Eval) focusing on the model's ability to understand the written code instead of the code generation task. The idea behind the benchmark is inspired by educational theory, which says that if someone can correctly evaluate other candidates' solutions, they will likely fully understand the given task. Means there is a difference in being able to generate code and understanding it.
They used the same concept of LLM-as-a-judge to use a group of proprietary and open-source models to judge whether a provided code is correct. The output could be (AC=Accepted), or different errors like WA (Wrong Answer) or RE (Runtime Error), to name a few. Their finding shows that the models that can generate the correct solution for a problem often cannot identify other correct answers! The paper suggests that the models can memorize ONE correct answer for a problem, while it is impossible to memorize all the correct answers.
They also found that open-source models are worse on this benchmark and perform worse than random guessing. The best model was Claude, that was able to get only 30% of the answers correctly.
Another RAG Improvement
📝 RARE: Retrieval-Augmented Reasoning Enhancement for Large Language Models [paper] [code]

This paper builds on top of the rStar framework. It combines Monte Carlo Tree Search with five different reasoning actions to help language models explore various paths to solve complex problems. rStar improves model reasoning capabilities without additional training by letting models dynamically choose between actions like proposing thoughts, asking sub-questions, or rephrasing questions. They introduce two new actions, A6 and A7, to improve commonsense reasoning.
Action A6, allows the system to generate targeted search queries based on the initial question and retrieve information from external sources. Action A7, focuses on sub-questions within the reasoning process, retrieving information to refine and improve intermediate answers. Additionally, the Retrieval-Augmented Factuality Scorer (RAFS) replaces the original discriminator in rStar. The RAFS evaluates reasoning paths by validating individual statements against retrieved evidence, ensuring both logical coherence and factual accuracy.
When tested on LLaMA 3.1 70B, RARE achieved SOTA results across multiple benchmarks. It outperformed GPT-4 on MedQA (87.43% vs. 83.97%) and MMLU-Medical (90.91% vs. 89.44%) in medical reasoning. Even with smaller models like LLaMA 3.1 8B, RARE showed significant improvements. It also showed strong performance in commonsense reasoning tasks. The results are noteworthy as they surpass or compete closely with GPT-4 and other leading models. It achieves these results without requiring any additional training or fine-tuning of the language models.
Improve LLM’s Reasoning
📝 AutoReason: Automatic Few-Shot Reasoning Decomposition [paper] [code]
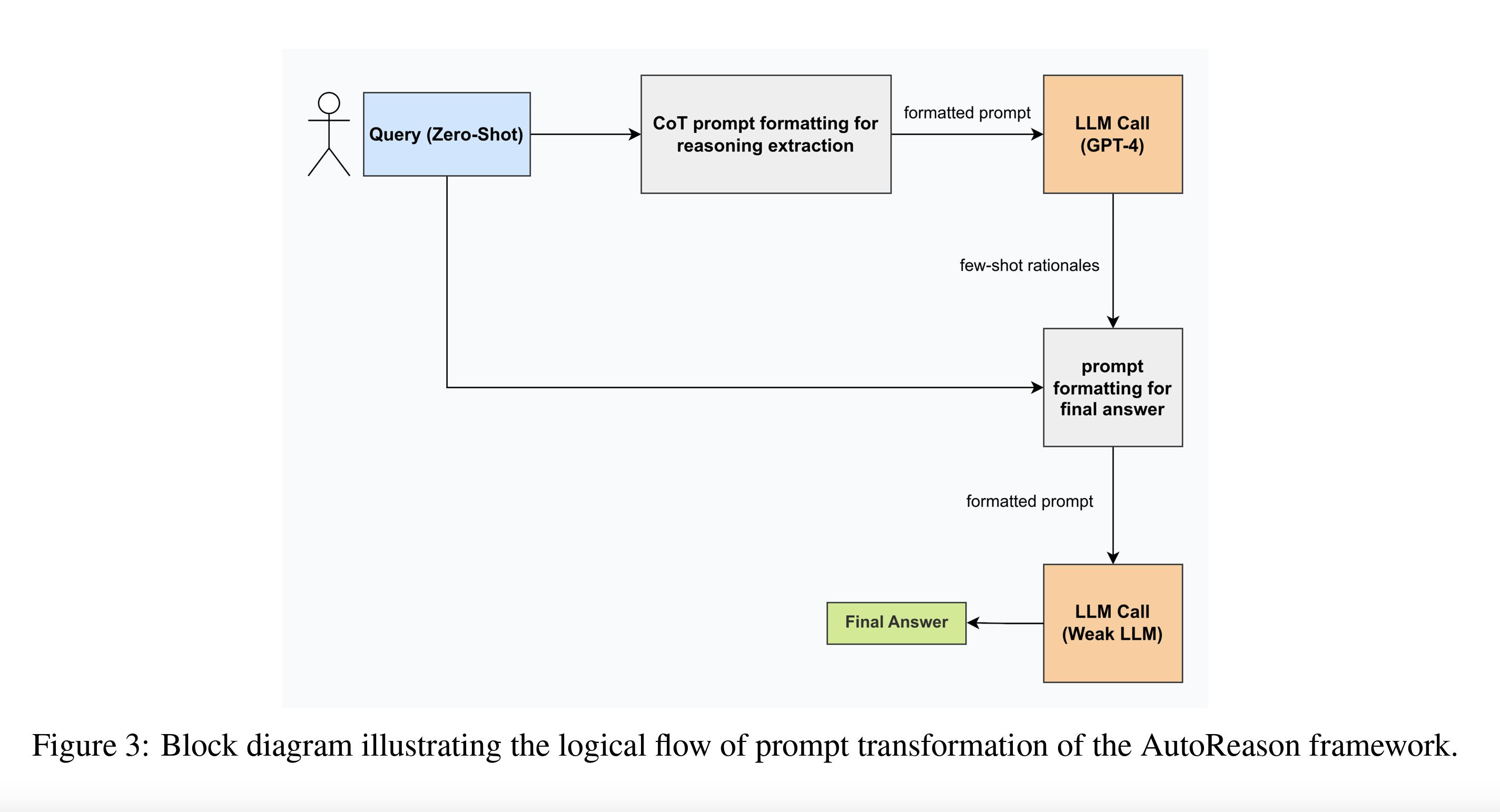
The paper introduces "AutoReason," a framework designed to improve the reasoning capabilities of LLMs by automatically generating reasoning traces based on a given query. It overcomes the limitations of traditional Chain of Thought (CoT) prompting by eliminating the need for expensive and time-consuming manual example crafting while providing flexible, adaptable guidance that can be uniquely tailored to each type of query.
"AutoReason is a multi-step reasoning framework designed for Large Language Models (LLMs) that effectively deconstructs zero-shot prompts from users into few-shot reasoning traces, also known as rationales." (from paper) It is done using a stronger model (GPT-4) to automatically decompose and generate rationales from the user's prompts. These rationales are then used to guide a weaker model (GPT-3.5-Turbo) in producing answers, eliminating the need for manual example creation.
The study claims significant improvements in reasoning capabilities, particularly on the StrategyQA dataset, where it boosted GPT-3.5-Turbo's accuracy from 55% to 76.6% and GPT-4's performance from 71.6% to an impressive 91.6%.
Better BERT
📝 Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference [paper] [blog post] [code]

"ModernBERT" is here! If you have been in the AI field for a while, you remember how big of a deal BERT was and why it needed an update!
The model is designed to have a significantly larger context length (8192 tokens) vs BERT's 512 and be computationally efficient while having a low parameter count. 139M for the base and 395M for the large version! Also, it results in a SOTA GLUE score. What more do we need? They adopted the advancements in LLM design to encoder-only models to achieve these improvements. It is possible to break the changes into two categories: Architectural and Efficiency improvements. The first group of changes known for stabilizing LLMs are as follows:
Removing bias to have more parameters for linear layers, rotary positional embedding that improves short and long sequences performance, pre-normalization block, and GeGLU activation function. The efficiency improvements consist of using a combination of alternating attention and flash attention mechanisms. The unpadding method helps with using hardware more efficiently instead of wasting on padding tokens, and lastly, the torch.compile() for training efficiency.
The model can be used for contextual search and classification with SOTA results. Refer to the paper or the introduction blog post to learn more about its results and why having an efficient and high-performing encoder-only model is important. Also, the model is also trained on coding data, which is a plus compared to other alternatives. So, it can be used for code retrieval and classification as well!
Final Words,
What do you think of this newsletter? I would like to hear your feedback.
What parts were interesting? What sections did you not like? What was missing, and do you want to see more of it in future?
Please reach out to me at nlpiation@gmail.com.