

NLPiation #27 - Scaling Through Diversity
Exploring how repeated sampling, graph integration, and efficient quantization are reshaping how language models learn and scale.

Welcome to my natural language processing newsletter, where I keep you up-to-date on the latest research papers, practical applications, and useful libraries. I aim to provide valuable insights and resources to help you stay informed and enhance your NLP skills. Let’s get to it!
Also, here's to an amazing 2025! (Just a bit early!)
Monkeys
📝 Large Language Monkeys: Scaling Inference Compute with Repeated Sampling [paper]
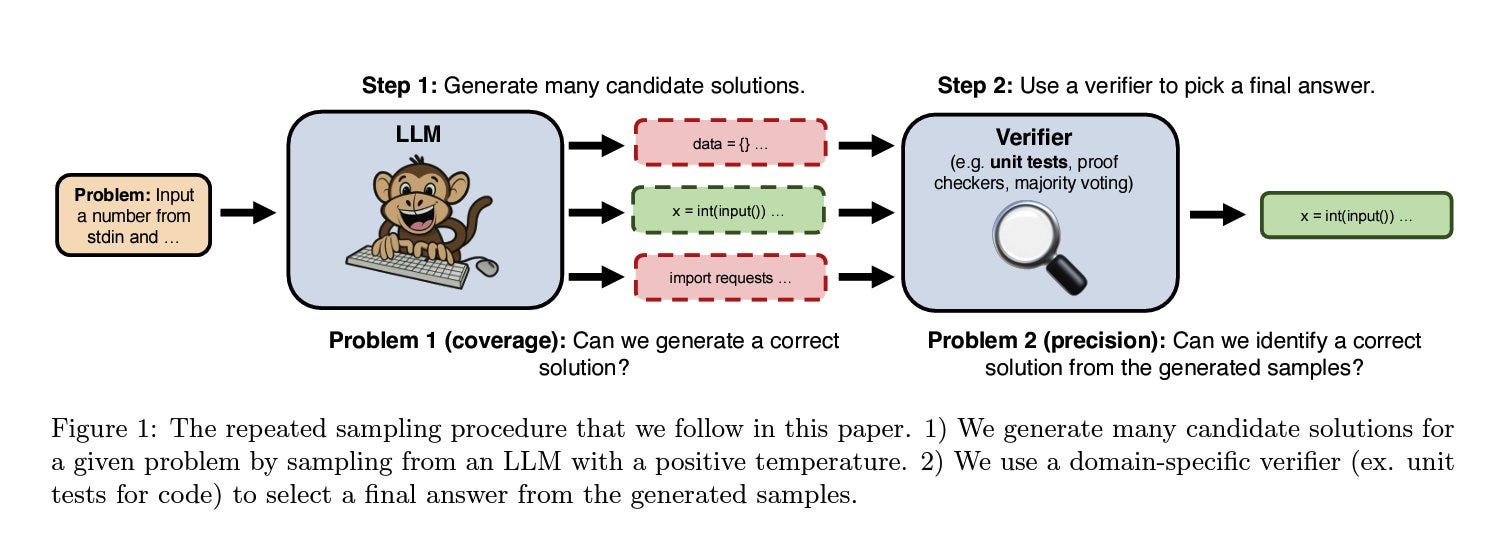
This paper proposes scaling the inference time as another dimension for scaling NLP models. They suggest that using the LLM to generate only one sample as the response is ineffective. The success of repeated sampling depends on two key factors: coverage and precision. Coverage refers to how many problems we can solve as we take more samples, while precision focuses on whether we can accurately choose the correct answer from the set of generated samples.
One of the open challenges is to have an automatic evaluation to measure the success rate. A method like a unit test is useful for finding a correct sample from a pool of candidates, but there are tasks like math problems that we don't have a proper way of identifying. The paper demonstrates an exponential power law relationship between coverage and the number of samples. This means that as the number of candidates generated by the LLM increases, the likelihood of having the correct solution in the pool also rises.
On the SWE-bench Lite, the current SOTA is 43%, achieved with a combination of GPT-4o and Claude 3.5 Sonet. By using the DeepSeek-Coder-V2-Instruct, which has a 15.9% accuracy on a single attempt, the score increased to 56% by generating 250 samples, raising the SOTA by 13%. To address cost concerns about generating 250 samples instead of one, they demonstrated that the DeepSeek model can outperform both GPT and Claude by generating 5 times more samples while still remaining cheaper.
Opinion: The concept of scaling models in terms of size and inference time is a fascinating topic, and it appears to be the foundation of OpenAI's newly released o1 model. This paper offers a preview of the method, providing insights into how it works and the scenarios where it performs best.
LLMs + Graphs
📝 LLaGA: Large Language and Graph Assistant [paper] [code]
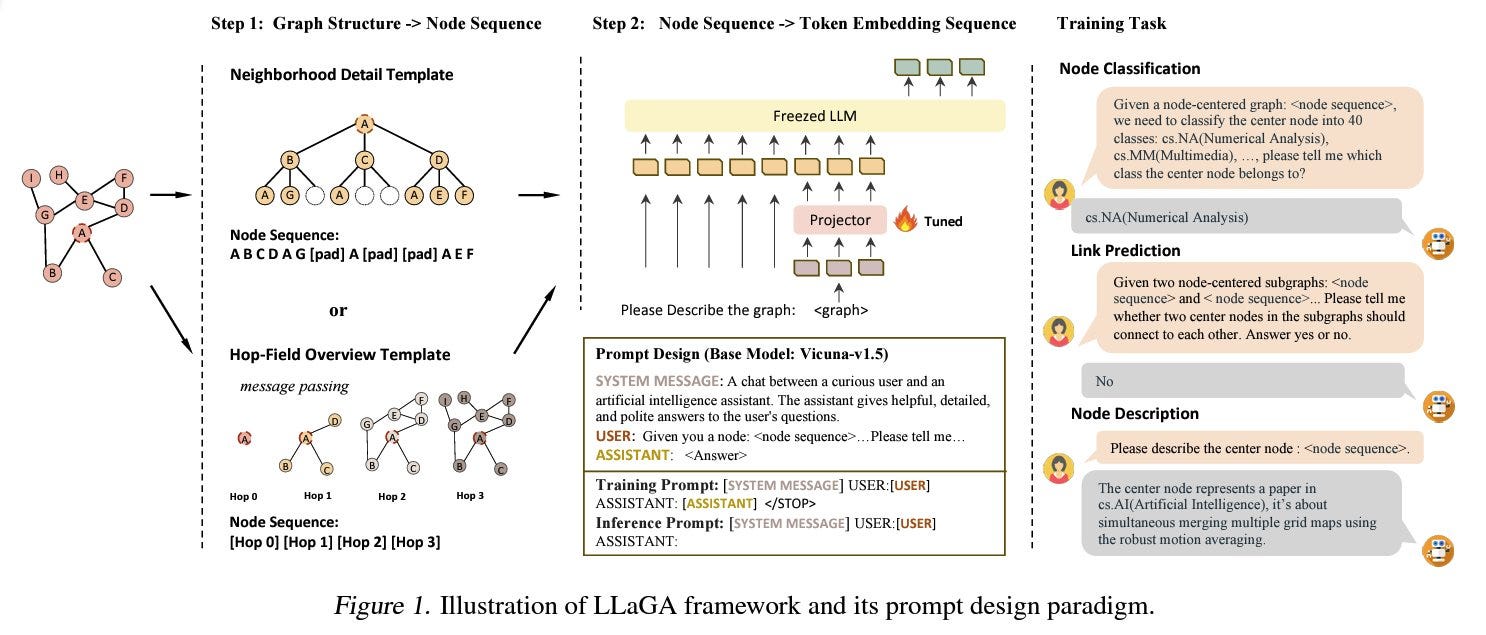
This paper presents a framework that integrates Large Language Models (LLMs) with graph-structured data, addressing the challenge of translating graph structures into a format compatible with LLMs. The main contribution is the introduction of two methods for converting graphs into node embedding sequences so it would be easier to integrate the graph data into token embedding space (using a learnable projector), which is interpretable by the LLMs.
Two key methods are 1) Neighborhood Detail template- an in-depth view of the central node & surroundings. 2) Hop-Field Overview template - summarized view of node's neighbourhood, extendable to larger fields. Together, they capture essential graph information.
The framework then trains a projector, making it possible to attend to the graph data and the token embeddings. It enables us to have an LLM-like conversation with the graph data. The projector can generalize to different tasks without further training. Extensive experiments show that LLaGA outperforms state-of-the-art graph models in both supervised and zero-shot scenarios across multiple datasets and tasks, including node classification, link prediction, and node description.

This framework leverages the LLM's built-in reasoning, avoiding fine-tuning. It's cost-effective and only requires tuning the projector, which is a simple MLP projector network.
Another Quantization
📝 FrameQuant: Flexible Low-Bit Quantization for Transformers [paper] [code]
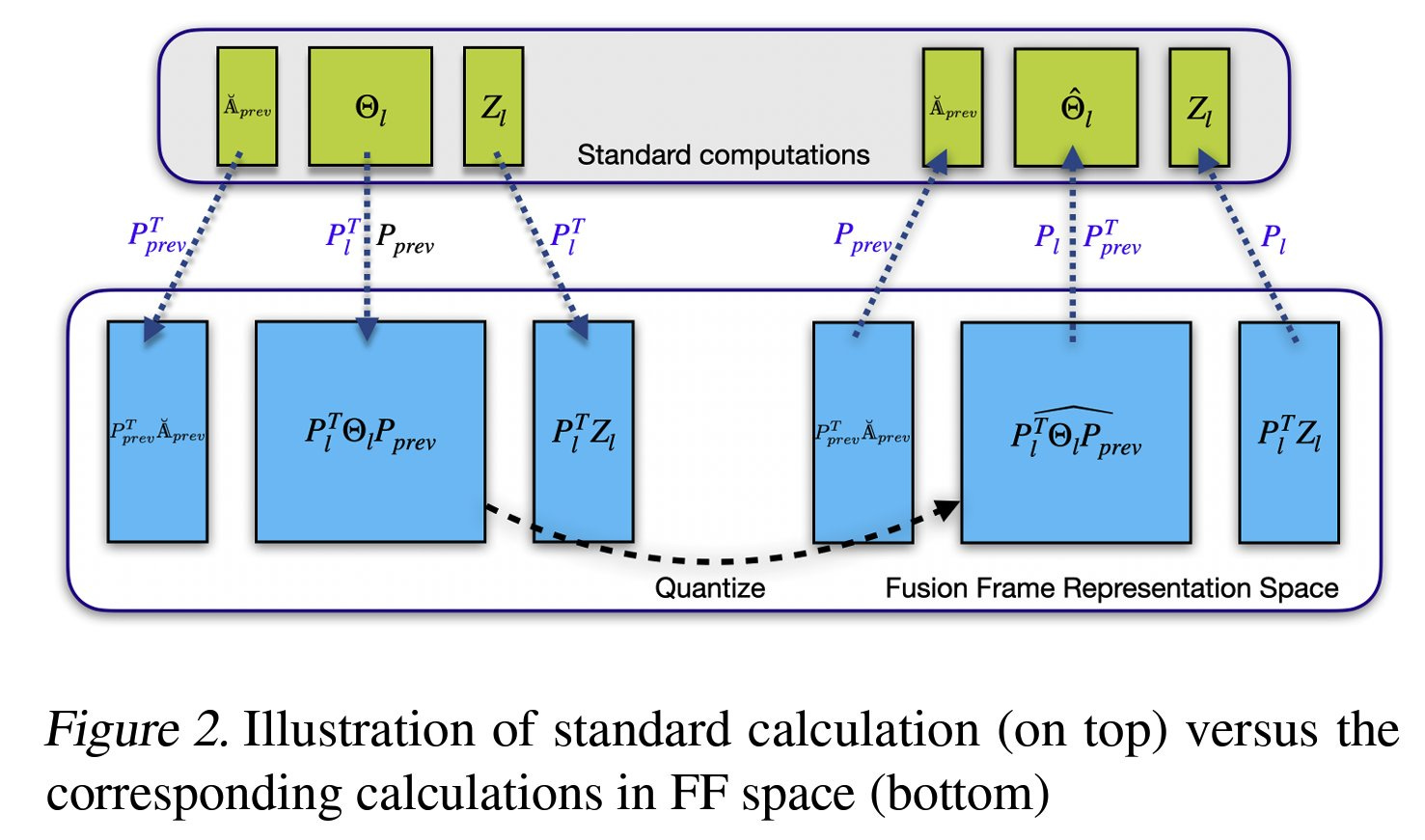
The research introduces a new quantization paradigm to reduce the transformer architecture memory footprint and maintain the model's accuracy. The idea is to leverage Fusion Frames (from Harmonic analysis), which splits a large frame into smaller subsystems. (become more manageable to analyze or process) They used FF to represent weight matrices in multiple overlapping parts, making the quantization more robust.
Weights in the Fusion Frame space undergo quantization to a low-bit representation. The approach mainly uses two-bit quantization but also supports fractional bit quantization (e.g., 2.1 or 2.2 bits) for flexible model size and accuracy control. They also use tricks like weight clipping to eliminate outliers. This ensures most weight values fall within a manageable range, reducing quantization error. As well as The iterative quantization algorithm (similar to GPTQ) method.
It iteratively adjusts quantized weights to minimize loss, ensuring the quantized model closely approximates the original model's performance. These techniques will improve the model's stability. Lastly, the model will undergo a de-quantization process at inference time.
The results show that using this technique on Vision Transformers and Large Language models achieves minimal performance loss. (and obviously noticeable efficiency gain) Also, larger models tolerate low-bit quantization better than smaller ones.
In-Context Learners
📝 Mixtures of In-Context Learners [paper]
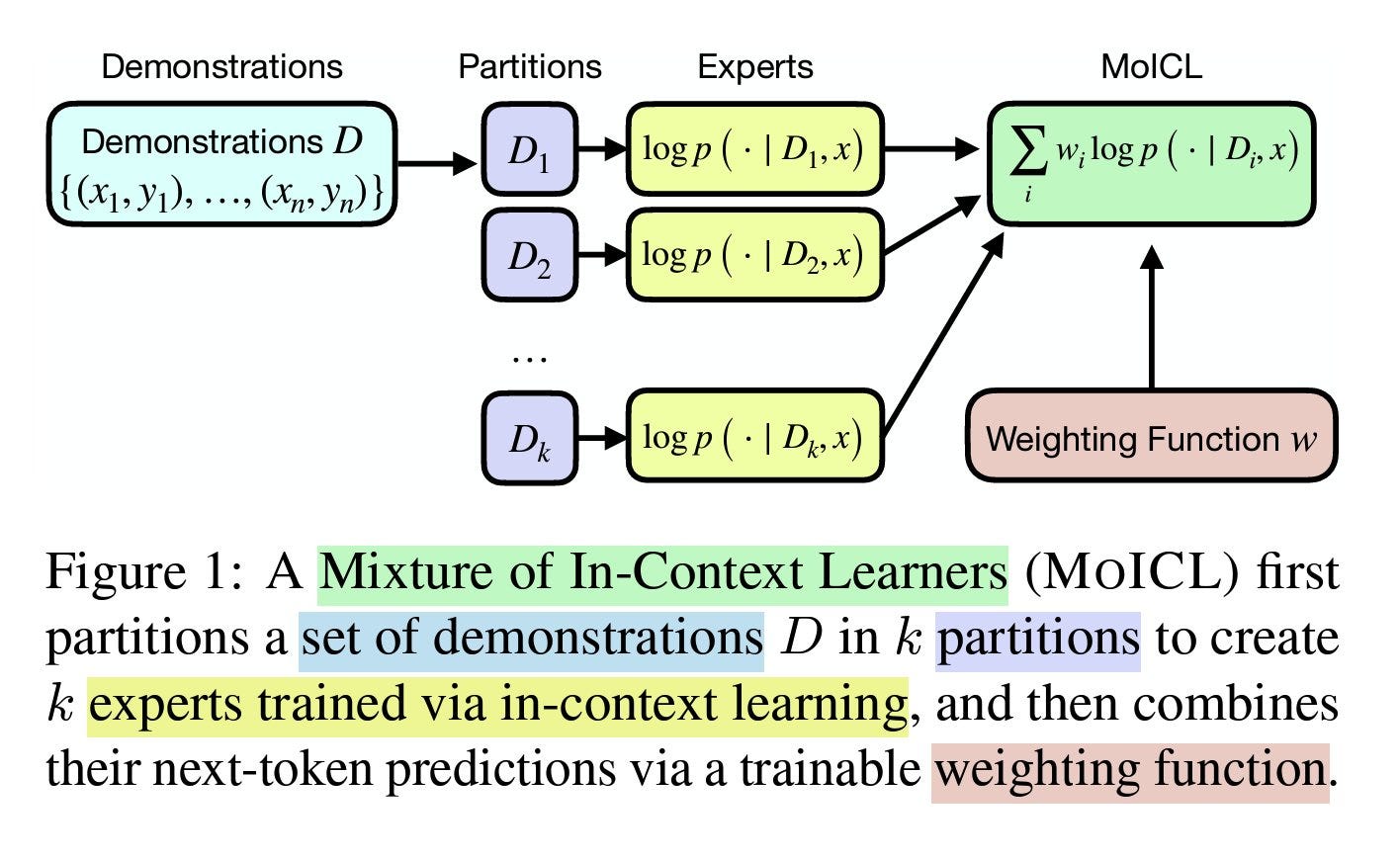
This paper introduces a method called MoICL that improves how LLMs learn from examples by smartly grouping and weighting different sets of examples, making the process faster and more reliable with fewer computational resources. In-context learning faces challenges with its sensitivity to both the quality and number of examples used, coupled with self-attention quadratic memory usage that increases computational costs as more examples are added to the model's context window.
This research suggests breaking down a large dataset of samples into k subgroups and using each group as the LLM's context. Then, a weighting function can be trained using a simple gradient-based optimization to understand which subgroups should contribute more to output. The MoICL method shows improvements over regular ICL by being more efficient with data, memory, and computational resources and showing more resilience when handling challenging scenarios like noisy or imbalanced datasets that typically cause problems for regular ICL.
It outperformed existing methods in 5 out of 7 classification tasks with up to 13% improvement while demonstrating exceptional robustness by handling out-of-domain data 11% better, imbalanced data 49% better, and noisy data 38% better than traditional approaches. For a deeper dive, the paper thoroughly analyzes how various parameters like model size, sampling strategies, and group configurations (and more...) affect MoICL's performance.
Final Words,
What do you think of this newsletter? I would like to hear your feedback.
What parts were interesting? What sections did you not like? What was missing, and do you want to see more of it in future?
Please reach out to me at nlpiation@gmail.com.