

NLPiation #26 - Detection, Reasoning, Transfer
Advancing LLMs through smarter attention mechanisms, thought-based reasoning, and efficient knowledge transfer.

Welcome to my natural language processing newsletter, where I keep you up-to-date on the latest research papers, practical applications, and useful libraries. I aim to provide valuable insights and resources to help you stay informed and enhance your NLP skills. Let’s get to it!
Lookback Lens
📝 Lookback Lens: Detecting and Mitigating Contextual Hallucinations in Large Language Models Using Only Attention Maps [paper] [code]

The paper addresses the issue of contextual hallucination, where LLM has access to input documents with the correct answers but still fails to locate them. They introduce the concept of Lookback Lens, which measures the proportion of attention heads focusing on the provided context compared to the newly generated tokens. This process is done separately for each head.
This feature can also be leveraged to train a classifier to predict hallucinations in the model. When applied through a Guided Decoding technique, this linear classifier resulted in nearly a 10% reduction in hallucinations on the XSum summarization dataset using LLaMA-7B. The advantage of this approach, compared to more complex methods like training classifier models on larger features such as the LLM's hidden state, lies in its simplicity and ease of transfer to other larger models without the need for additional training. They reported a 3.2% reduction in hallucinations on LLaMA-13B using the same classifier.
Opinion: The researchers primarily concentrate on addressing the hallucination problem in model outputs, where the model generates responses based on its internal knowledge—an issue that is notably challenging to resolve. However, a more intriguing challenge is in enhancing the model's accuracy in identifying facts from a given context. This improvement would directly benefit the quality of RAG pipelines, which, at the moment, may require advanced techniques to enhance response quality. This paper presents a straightforward and transferable technique that could have a significant impact on the field!
Buffer of Thought
📝 Buffer of Thoughts: Thought-Augmented Reasoning with Large Language Models [paper] [code]
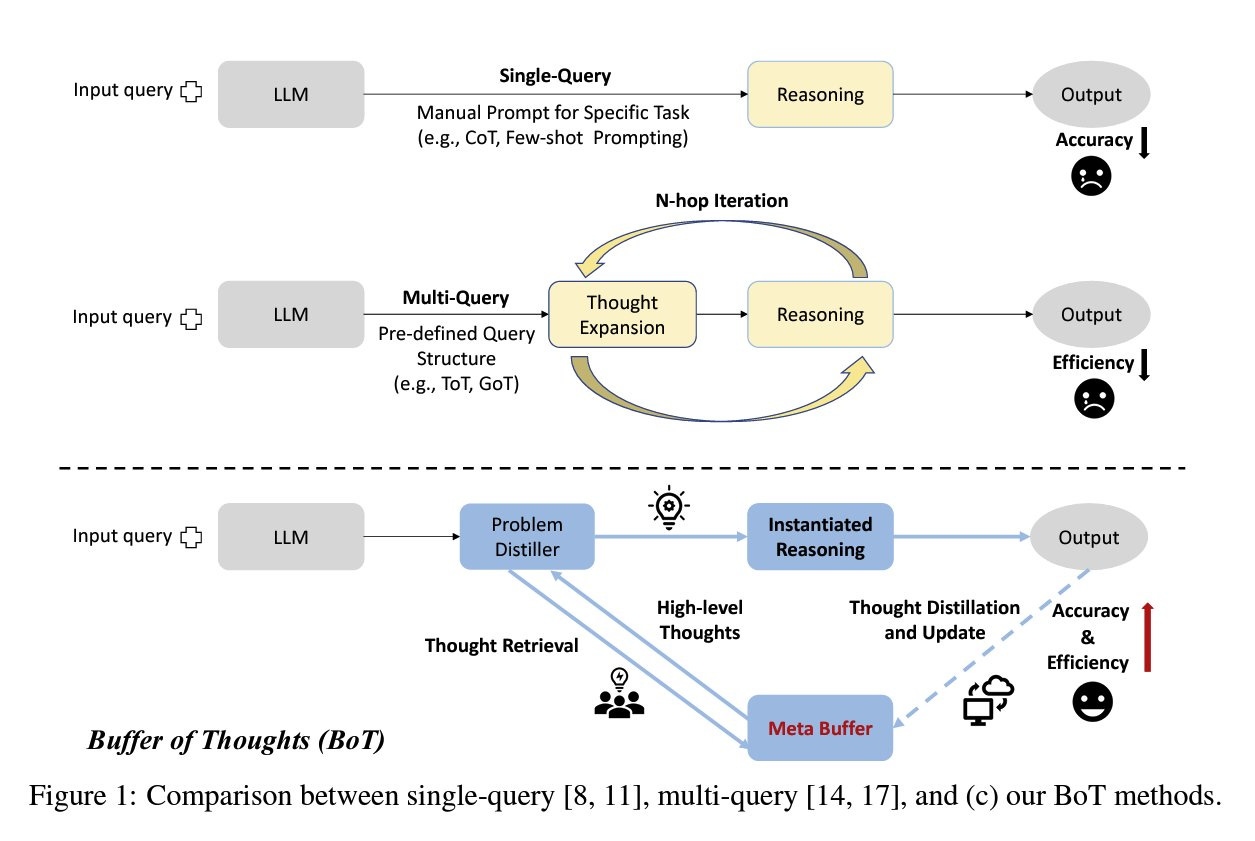
This paper proposes the idea of using a bank of thought templates that help the LLM to improve its reasoning. Compared to previous methods, it is more efficient, robust, and accurate! It is done by introducing the idea of a meta-buffer, which is a library of different high-level thoughts (templates) and the buffer-manager to update the library based on the newly solved problems. The combination of the two makes this technique dynamic across tasks.

The attached image illustrates these templates, which enhance the robustness of LLMs. By applying a consistent thought template to similar tasks, the LLM maintains a uniform thought process across various problems. This approach is more efficient since it doesn’t require examples (few-shot) or repeated requests (ToT/GoT) to improve reasoning. The template, which is extracted based on successful responses, gets improved as the model handles more problems.
This technique shows that the 8B variant can surpass LLaMA-70B in reasoning capability. It also led to significant improvements in various reasoning tasks, such as a 51% boost in checkmate-in-one, 20% in geometric shapes, and 11% in the game of 24, among others.
LLM for Understanding UI
📝 Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs [paper]
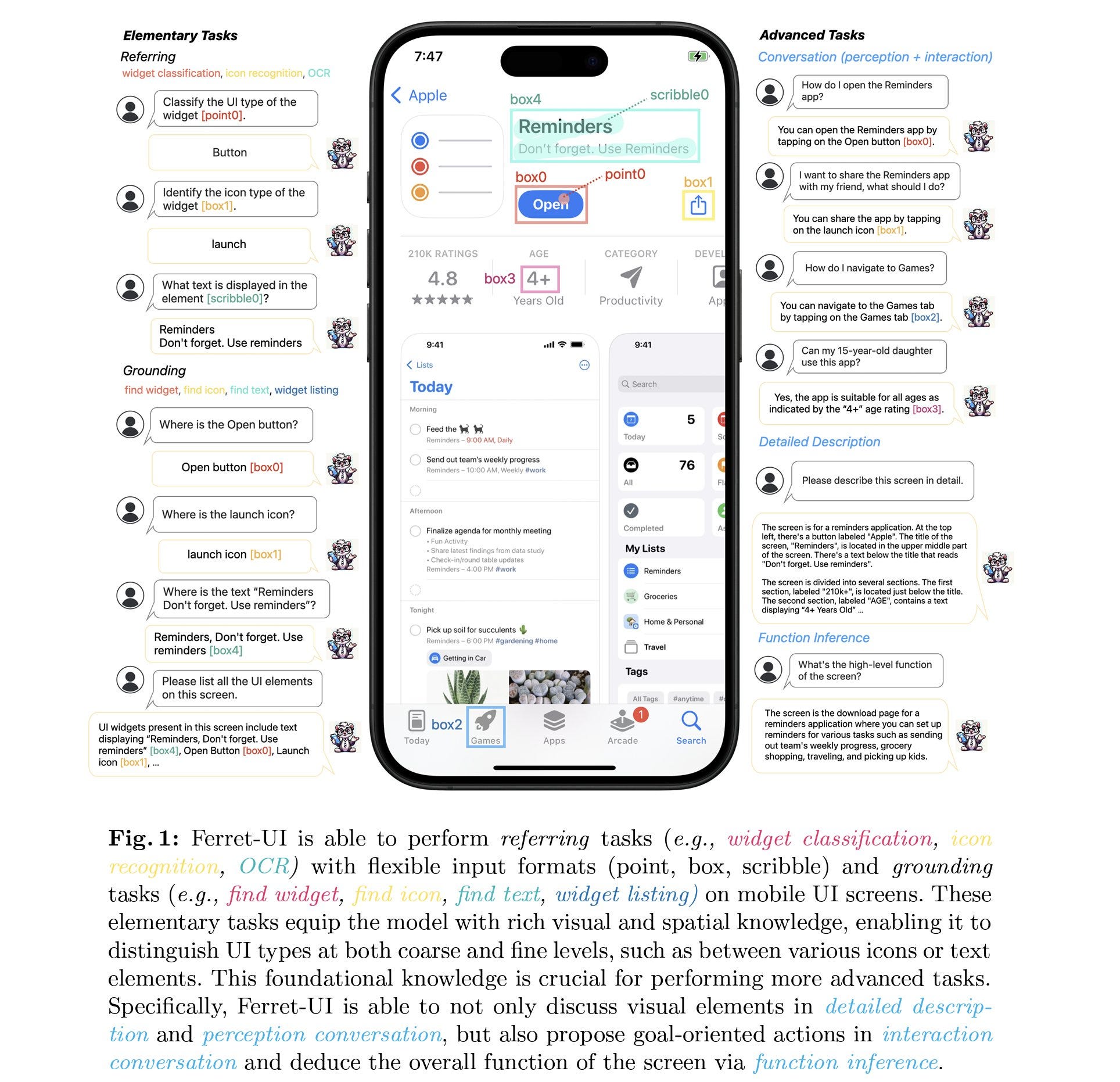
This paper by Apple represents the first UI-centric MLLMs capable of effectively executing referring, grounding, and reasoning tasks. This model can interact with mobile devices or even generate UI...
Two important concepts are referring which involves the model's ability to use specific regional information from the input screen (like OCR), while grounding is the model's capacity to identify precise locations in its outputs (like finding specific widgets). This model builds upon the Ferret model with several enhancements. A key improvement is the implementation of an "any-resolution" technique. This approach dynamically resizes and segments the input screen, enabling the model to effectively handle various aspect ratios.
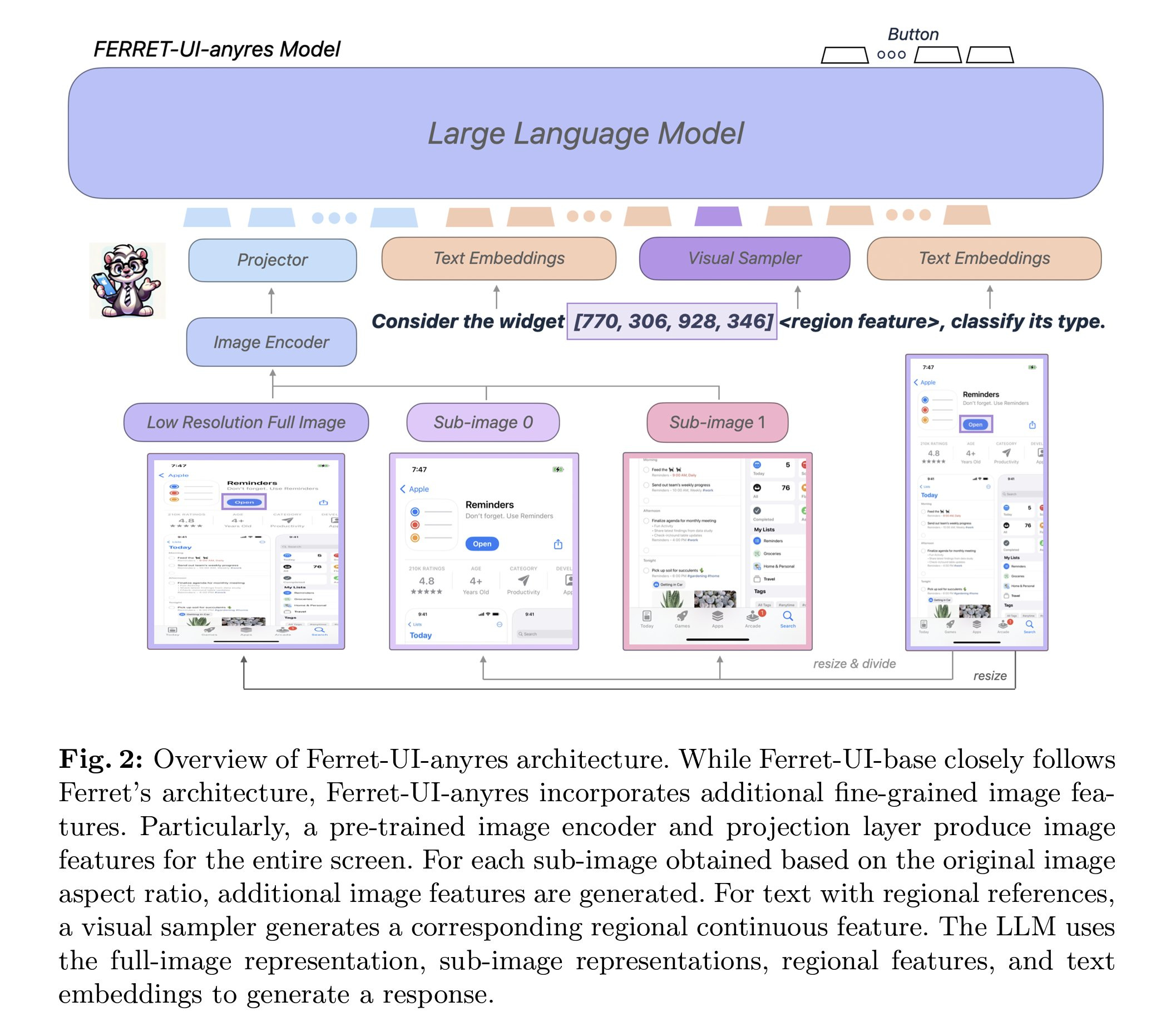
They used GPT-4 to generate training data on detailed descriptions, conversation perception and interaction, and function inference. This prepares the model for nuanced discussions about visual elements, goal-oriented action planning, and screen purpose interpretation. The paper also released a set of benchmarks to compare the effectiveness of the proposed method with other available MLLMs like GPT-4, Fuyu, and CogAgent. The Ferret-UI model provided significant improvement over available models on both elementary and advanced tasks.
Transfer Knowledge
📝 Transferring Knowledge from Large Foundation Models to Small Downstream Models [paper] [code]
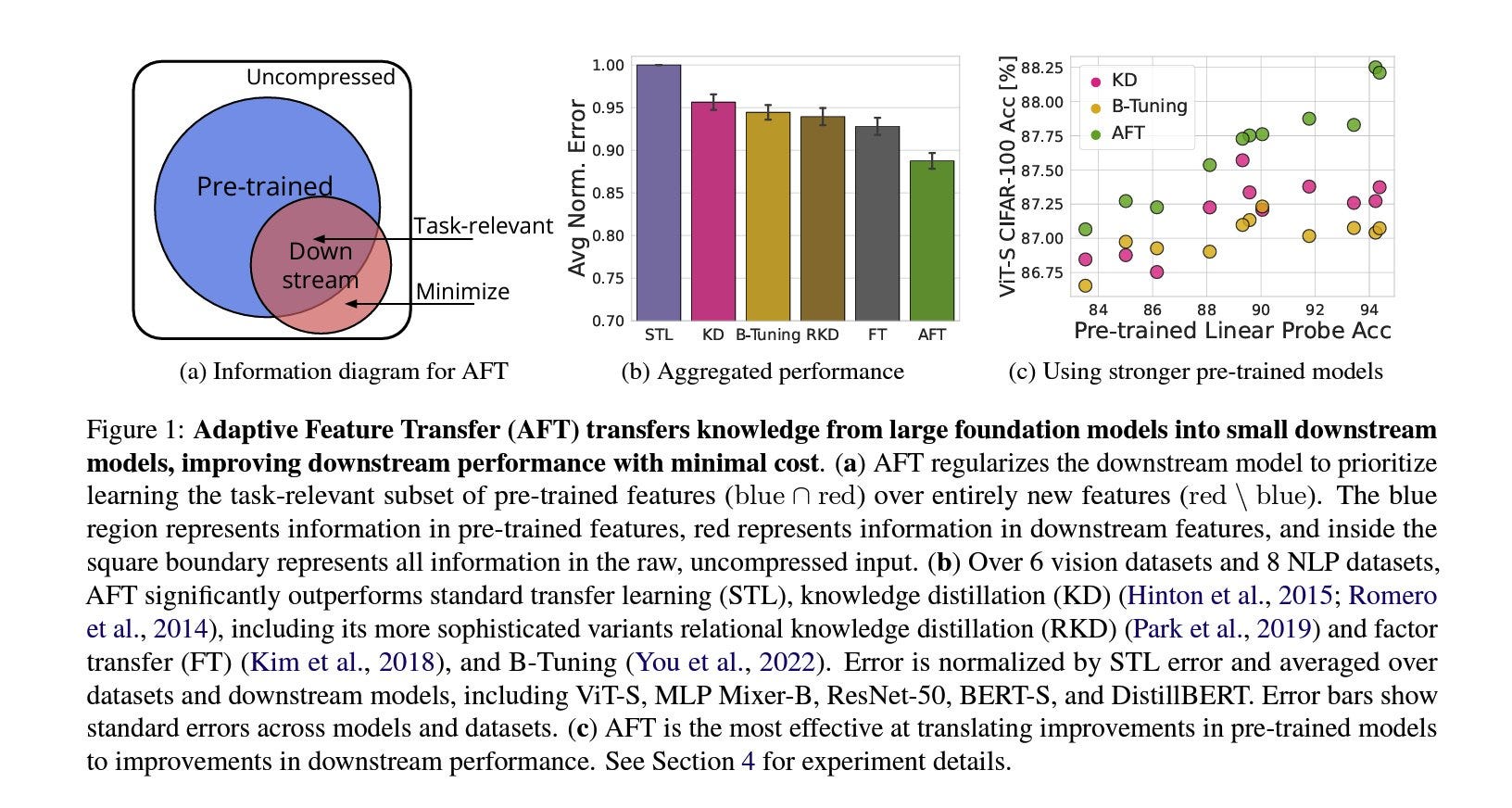
This paper proposes a new transfer learning approach, enabling the fine-tuning of smaller models by using the features extracted from larger models rather than simply transferring weights. While transfer learning is a popular technique, it still has obvious limitations, such as (1) copying unnecessary information to the downstream model, which requires fine-tuning. As model sizes grow, this process becomes inefficient. (2) Does not provide an answer on how to train a model that integrates knowledge from multiple existing models.
The Adaptive Feature Transfer (AFT) technique is designed to address these limitations by modifying the Knowledge Distillation (KD) objective. This means that instead of directly predicting the pre-trained features, the modification learns a transformation that is applied to them. This allows the downstream model to encode only a subset of the pre-trained features, filtering out irrelevant or harmful information.
This method results in an average reduced error rate in downstream models compared to the previous compression methods. It also reduces the cost of transfer learning since the models generalize better, and there is potential to improve the performance. The paper presents comprehensive ablation studies that examine the inner workings of the method. (How, and why it works) If you are interested in transferring knowledge from large to small models, you will find this paper a great read.
Final Words,
What do you think of this newsletter? I would like to hear your feedback.
What parts were interesting? What sections did you not like? What was missing, and do you want to see more of it in future?
Please reach out to me at nlpiation@gmail.com.