

NLPiation #25 - Experts, Knowledge, Memory
Exploring the complexity of expert mixtures, knowledge integration, and memory in modern NLP models.

Welcome to my natural language processing newsletter, where I keep you up-to-date on the latest research papers, practical applications, and useful libraries. I aim to provide valuable insights and resources to help you stay informed and enhance your NLP skills. Let’s get to it!
Millions of Experts
📝 Mixture of A Million Experts [paper]
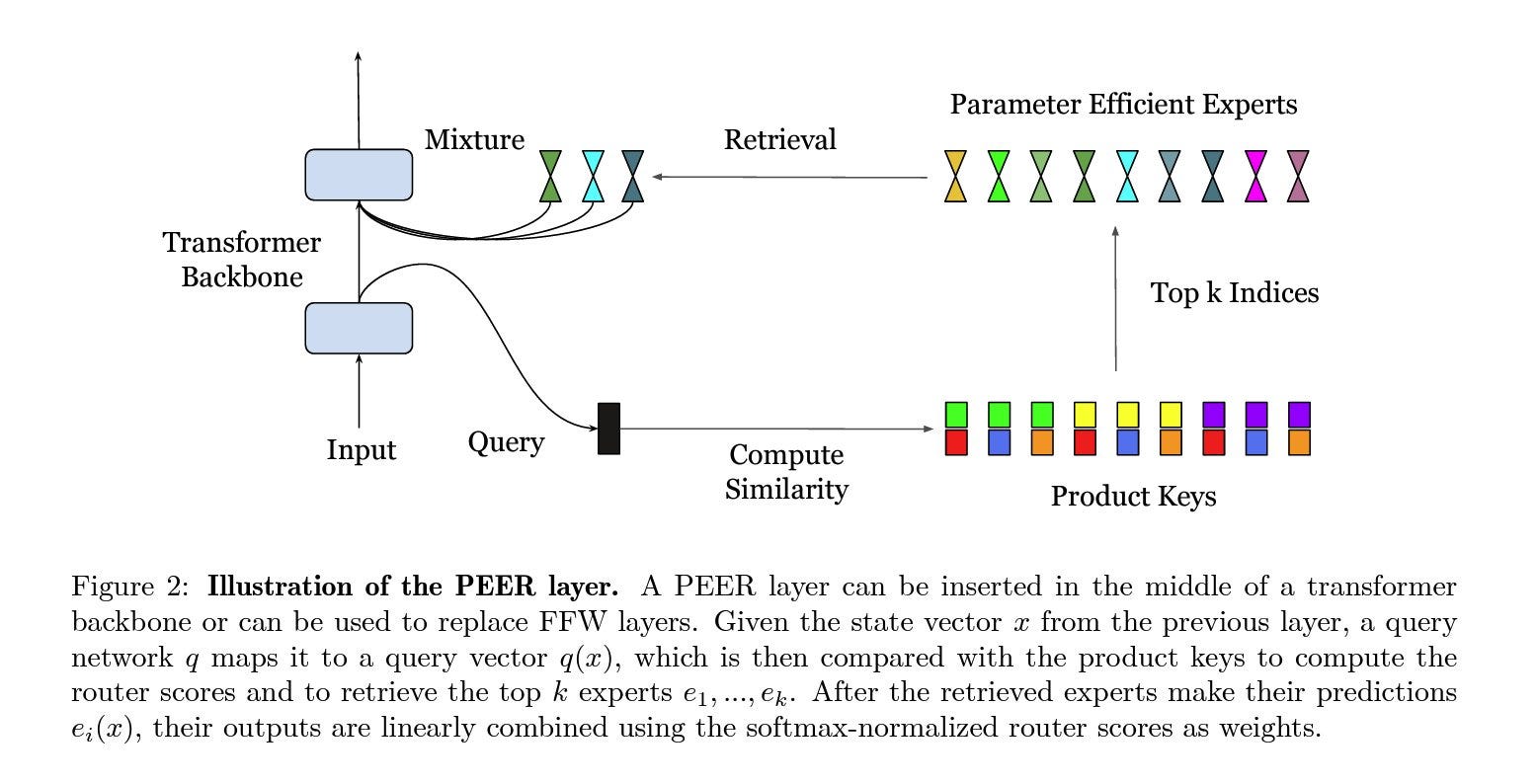
This paper introduces a technique that enables the creation of a Mixture of Experts (MoE) model with a large number (over 1M) of small experts while staying computationally efficient. It is called Parameter Efficient Expert Retrieval (PEER). MoE models are typically effective for efficient scaling, as the scaling law indicates that increasing the number of experts enhances the model's performance. (PS: These models are life-long learners, allowing for the easy addition of new experts to expand their knowledge.)
The primary contribution of this paper is the introduction of a learnable router. This router selects the most suitable experts by using product key retrieval to identify the top K experts, whose weighted average is then used to generate the output. Secondly, they used single-neuron MLP to implement each expert. This allows the router to create its optimal network by combining multiple experts. Consequently, the capacity of each layer can be adjusted by selecting a different number of experts.
The PEER method demonstrated significantly better performance compared to standard MoE models, achieving a lower perplexity score while maintaining computational efficiency. An in-depth ablation study was conducted to validate the effectiveness of this technique.
Analyze MoE
📝 A Closer Look into Mixture-of-Experts in Large Language Models [paper] [code]
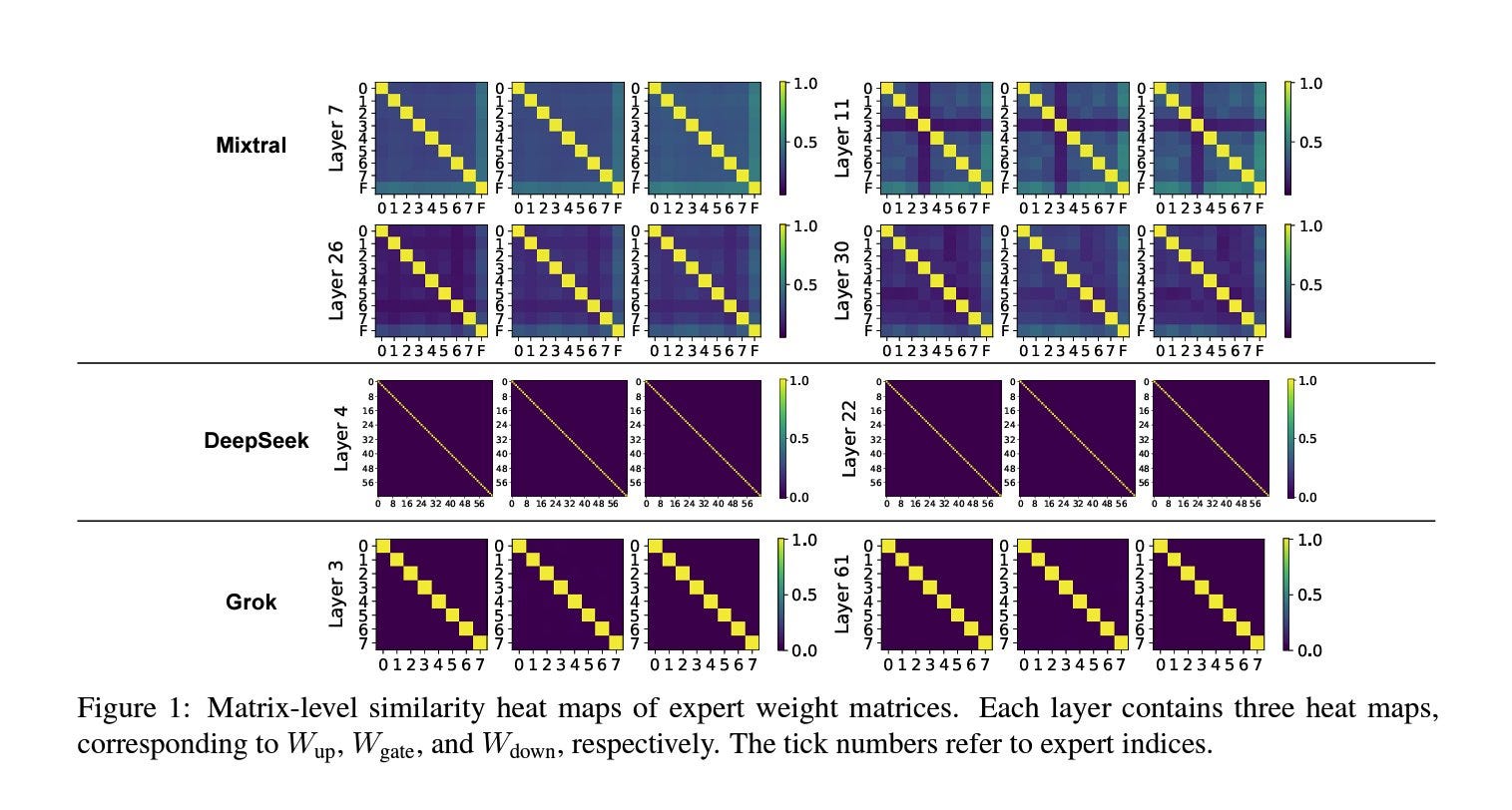
The MoE technique has recently been the go-to strategy for training efficient and highly performant LLMs. This research explores the method in more detail to find the best practices. They concentrate on the Mixtral 8x7B, DeepSeekMoE, and Grok-1 models, aiming to identify trends in model parameters and analyze their behaviour when processing text inputs. They also used Mistral 7B to compare the findings with vanilla transformer architecture.
The paper offers valuable insights and recommendations, making it a must-read for anyone planning to leverage MoE architecture. I will highlight a few interesting findings here.
1. The experts are fine-grained, with each neuron functioning as an expert. Essentially, the router (gate) embedding decides which expert (group of neurons) to select, and the gate's weights indicate which neuron is the most significant.
2. Given the similarity between experts in different layers, using more experts in the initial layers and fewer experts as you get closer to the output layer is recommended.
3. Gate usually selects experts with higher output norms. Choosing experts based on it makes sense.
4. The close similarity between Mixtral and Mistral model weights suggests Mixtral used an initiation technique, resulting in similar experts. In contrast, the other two models, trained from scratch, show weaker correlations, which is more desirable.
The paper contains numerous additional interesting findings that I haven't covered here, making it a worthwhile read for comprehensive insights.
Root of Hallucination
📝 From RAGs to rich parameters: Probing how language models utilize external knowledge over parametric information for factual queries [paper]
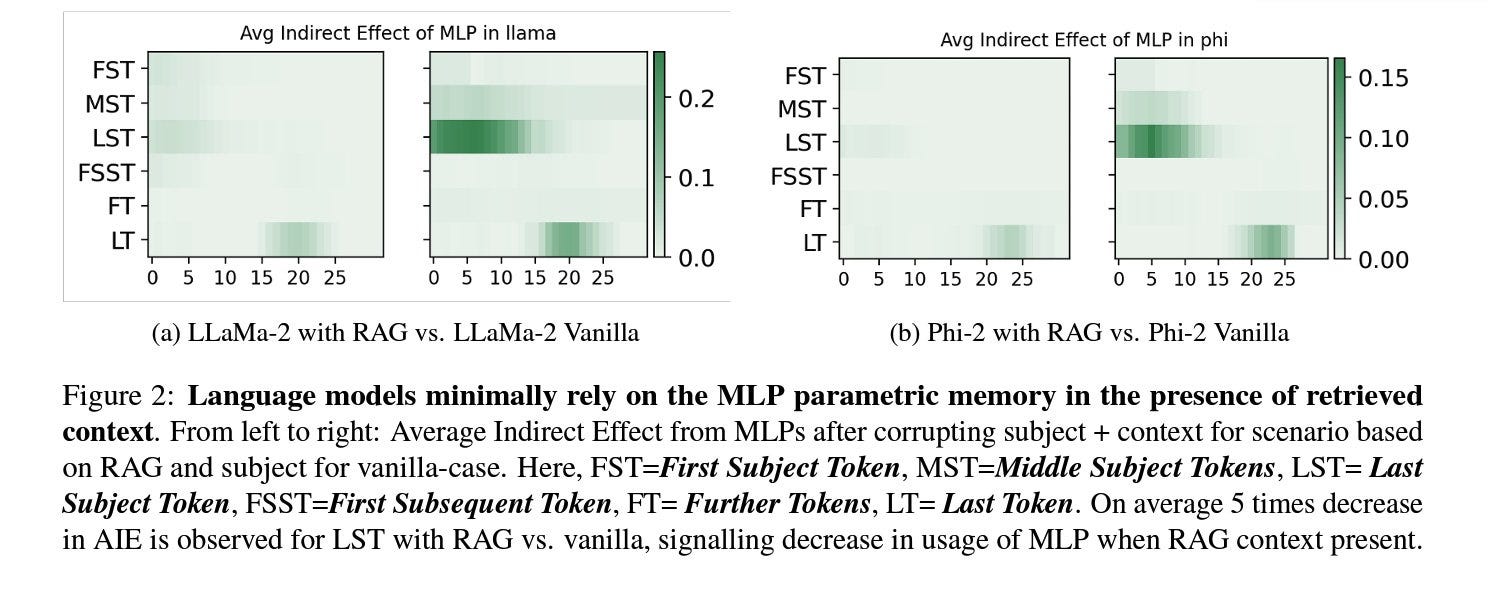
This paper explores the inner workings of a RAG pipeline, its process of answering questions, and the reasons it reduces hallucinations. They study the model's behaviour to assess how much it depends on its internal knowledge compared to the given context. This analysis uses both causal tracing, which examines MLP activations, and attention knockout and contribution methods that focus on attention scores.
Their primary conclusion was that the model relies significantly less on its parameter memory to answer questions compared to the context. This outcome aligns with the expected behaviour and serves as evidence supporting it. They also identified a shortcut behaviour where the model focuses more on the provided context than on the subject of the asked question. Their findings were consistent across both LLaMA and Phi models. It's a straightforward paper which sheds some light on how LLMs work.
External Memory
📝 Memory³: Language Modeling with Explicit Memory [paper]
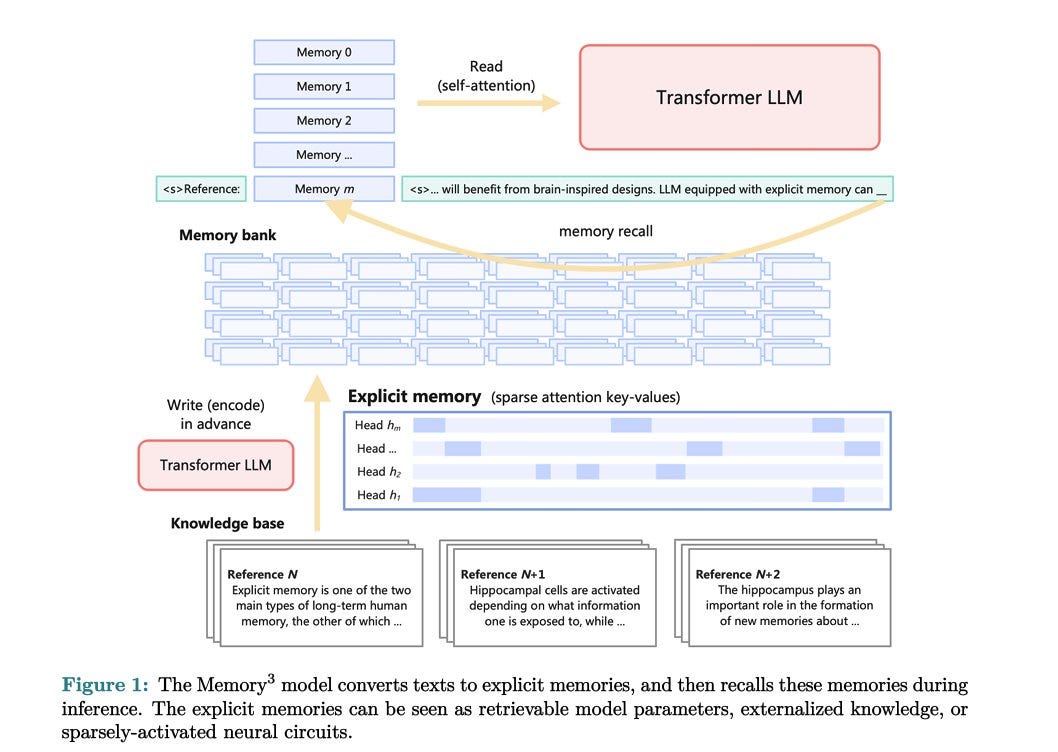
This study shares the concept of externalizing knowledge to complement model weights and context-based key-value memories. This approach reduces the model's size while outperforming techniques such as RAG. This approach is compared to the idea that LLMs currently learn inefficiently, like memory-impaired patients acquiring skills through repetition. This approach aims to equip LLMs with an explicit memory system as efficient as human memory, improving their learning process.
This method transforms a knowledge base into sparse attention key-value pairs, which can be seamlessly integrated into any model's attention layer. The resulting dataset is highly compressed, making this approach more efficient than Retrieval-Augmented Generation (RAG). The core concept is to train a model primarily on abstract knowledge, avoiding learning specific facts or knowledge. This model can then access and use explicit memory as needed, drawing on specific information when required.
Their 2.4B parameter pre-trained model surpassed the performance of similarly sized models and remained competitive with models 5 to 20 times larger on few-shot evaluation.
Opinion: I believe it is a great idea where we can have a small-ish model (2B) coupled with a large external memory stored on terabytes of disk space. This external memory can be updated and expanded as the model is used, allowing the model's knowledge to grow without increasing its size. Basically, the model maintains a constant size while its accessible knowledge base continuously improves.
Final Words,
What do you think of this newsletter? I would like to hear your feedback.
What parts were interesting? What sections did you not like? What was missing, and do you want to see more of it in future?
Please reach out to me at nlpiation@gmail.com.