

NLPiation #24 - Accelerating Contextual Compression for Multimodal Understanding
Unlocking efficiency by Innovations in NLP for Speed, Context, and Multimodal Insights

Welcome to my natural language processing newsletter, where I keep you up-to-date on the latest research papers, practical applications, and useful libraries. I aim to provide valuable insights and resources to help you stay informed and enhance your NLP skills. Let’s get to it!
Draft & Verify
📝 Draft & Verify: Lossless Large Language Model Acceleration via Self-Speculative Decoding [paper] [code]

This study examines the increasing cost of inference in Large Language Models (LLMs) and pinpoints autoregressive decoding as the primary bottleneck. This paper expands on the concept of speculative decoding, where a smaller drafting model generates a sequence of tokens as a draft, which is then evaluated by a verification model in a single forward pass. The verification model either confirms or rejects the tokens.
They argue that using an extra model adds overhead to GPU usage. The authors propose the Self-Speculative process, using a single LLM for drafting and verification. By skipping layers during drafting, the process speeds up without significantly impacting model capabilities. The drafting model generates K tokens until confidence drops below a threshold. The verification model evaluates the generated tokens, decides whether to keep them and predicts the next token (K+1) to guide the next stage of the drafting process.
This technique achieves a 1.99x speedup without compromising the model's performance on summarization and coding tasks. Most impressively, this technique is plug-and-play and can be integrated with any model.
Opinion: One minor concern is the paper's reporting only the ROUGE-2 metric to evaluate summarization performance. It seems unusual to focus exclusively on this single metric... Still, I'm confident that if the method shows promise in R-2, it will also prove effective in terms of R-1 or R-L. It's just strange...
Contextual Positional Encoding
📝 Contextual Position Encoding: Learning to Count What's Important [paper]
This paper highlights the problem with the current positional embedding technique and the recency bias it introduces. They propose the idea of context-aware position encoding.

It uses the concept of gates, where the attention head uses its query/key vectors to find where the attention should focus. It allows one head to concentrate on paragraphs while others focus on sentences, words, or even tokens, effectively the same as the current PE method. The position vector, calculated by the cumulative sum of the gates vector, will be added to the key vector. This allows the query to use them in the attention mechanism. It's the same process as the current dominant transformer architecture.
Since the query vector in each layer is different, the model has access to different units of distance (or position encoding vectors) while processing a text. This means it could identify patterns such as new lines or sections in a text. (Image below)
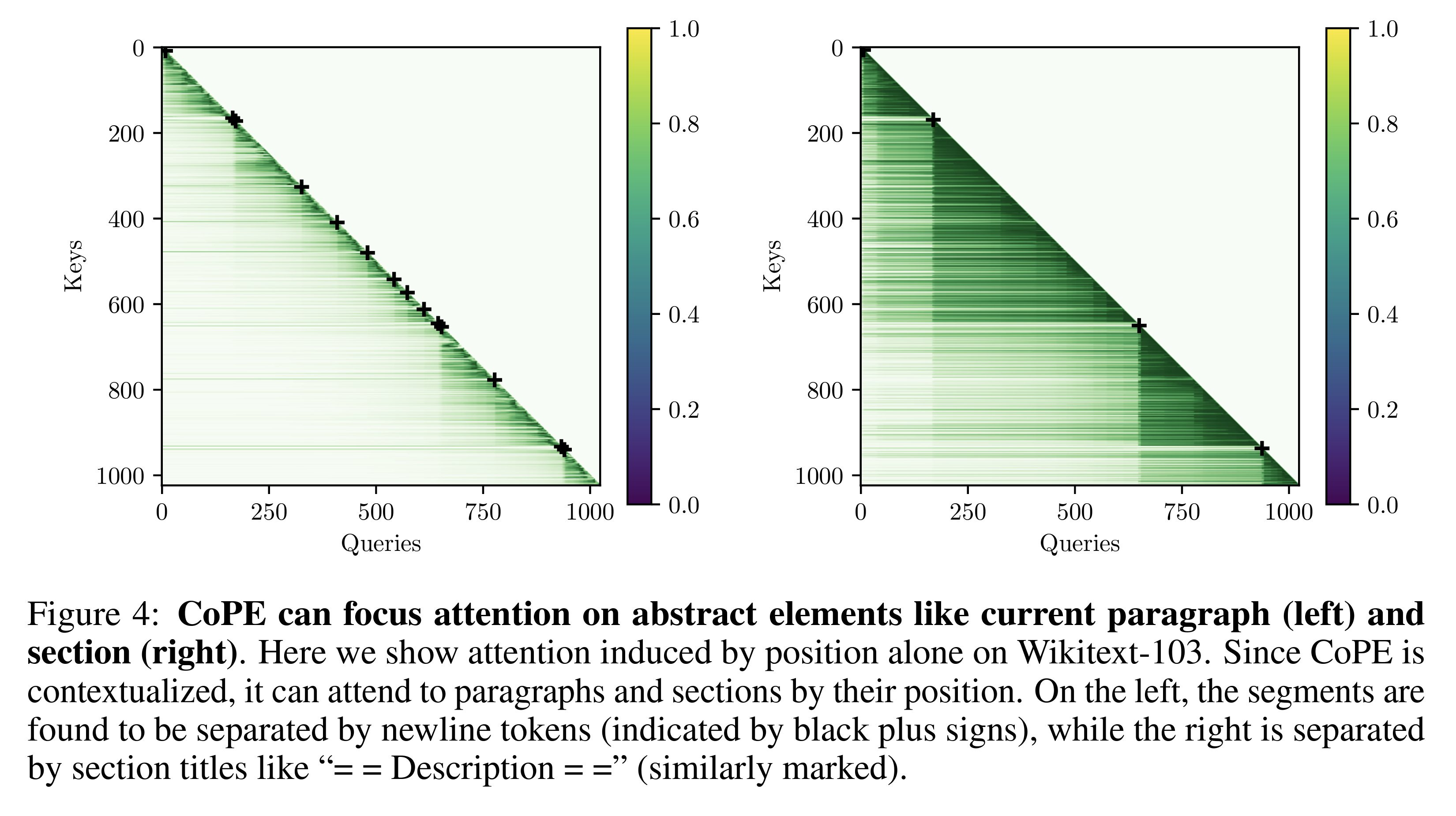
The proposed method was tested on tasks such as text generation, coding, flip-flop, selective copy, and counting. (details in the paper) The results show that the model can outperform the original architecture convincingly in all the benchmarks. The only shortcoming of the paper is that they used small-scale models (size of GPT-2 for text generation or 20M parameters model for coding) to test their theory. I don't see any reason why the results would not transfer to larger models. But liked to see the results.
Compressing LoRA
📝 NOLA: Compressing LoRA using Linear Combination of Random Basis [paper] [code] [webpage]
This paper introduces a novel technique for efficient fine-tuning that employs smaller adaptors compared to LoRA. This results in models that retain the same capabilities.
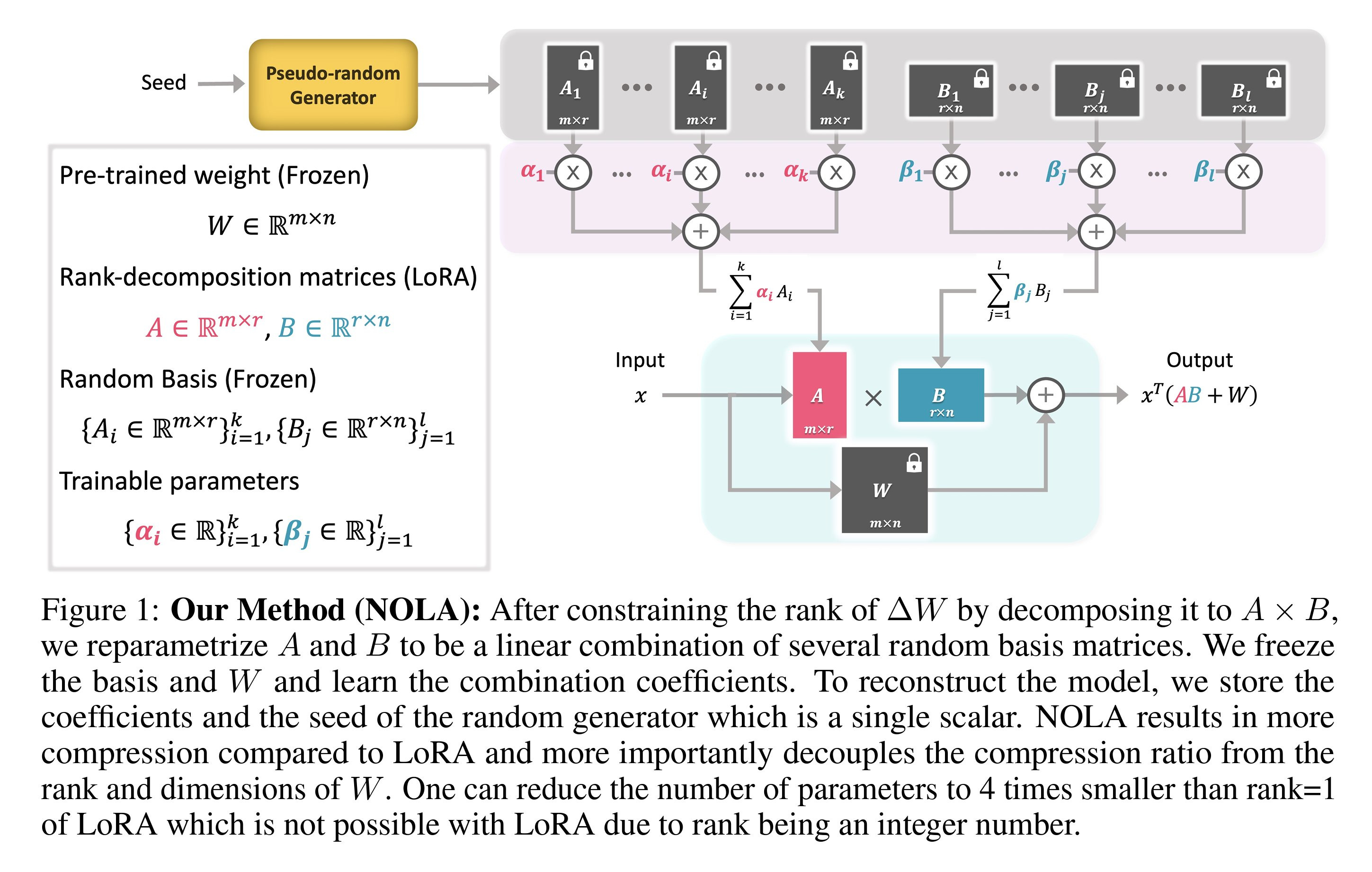
They identified that LoRA's limitations are influenced by the architecture and pretrained weight sizes. (m and n) This means it cannot compress beyond rank 1, resulting in large adaptors when the goal is to host a large number of adaptors for various applications. The researchers proposed an alternative by decomposing the A and B matrices into a combination of several randomly generated matrices (frozen) and their respective coefficients (learnable) for each one. So, we only learn a number of coefficients during tuning.
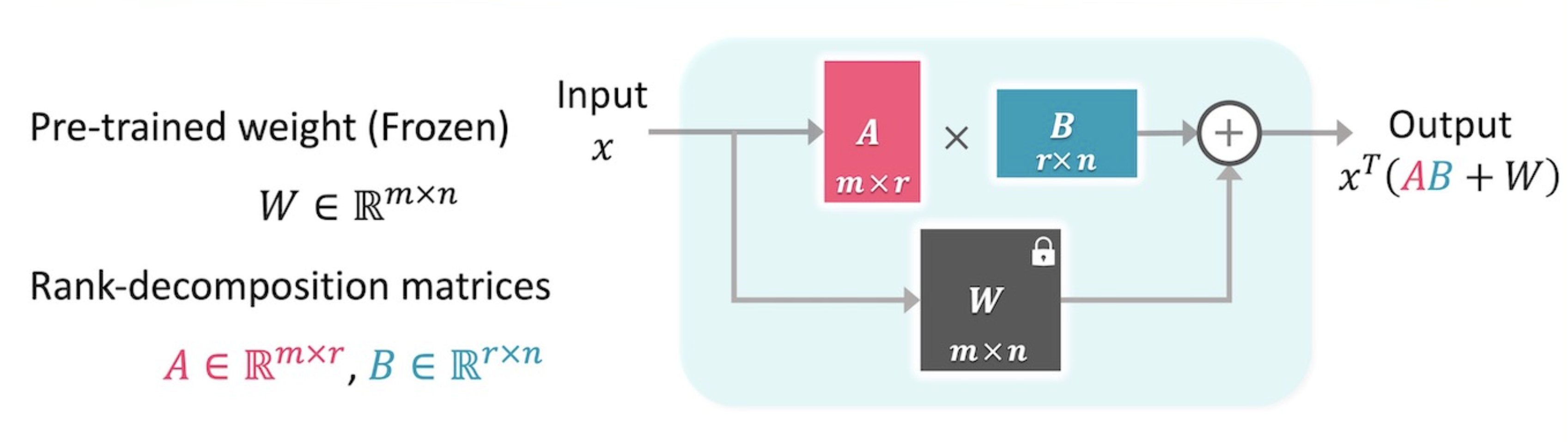
The remainder of the process remains the same as in LoRA. We use the weighted sum of the random matrices and their coefficients to construct the A and B matrices, which are then used during fine-tuning, but with a significantly smaller number of trainable parameters. This approach makes the adaptors 20 times more compact compared to the smallest LoRA size without any loss in accuracy. It has been demonstrated to be effective in text generation (LLaMA2) and image processing (ViT) models.
They assert that this technique will allow us to host 10,000 variants of LLaMA-2 (70B - 4bit) on a GPU with 48GB of memory, which is remarkable!
Opinion: Considering that tuning models with LoRA were already challenging, I believe that NOLA might add even more complexity to the process. Although it is possible to train high-quality models with NOLA, achieving such a model may be more difficult. However, this needs to be tested!
Table Understanding
📝 Multimodal Table Understanding [paper] [code]
This paper introduces the "multimodal table understanding" problem, aiming to enhance the ability of LLMs to comprehend tables. It focuses on improving the accuracy of responses to questions about specific rows or columns.
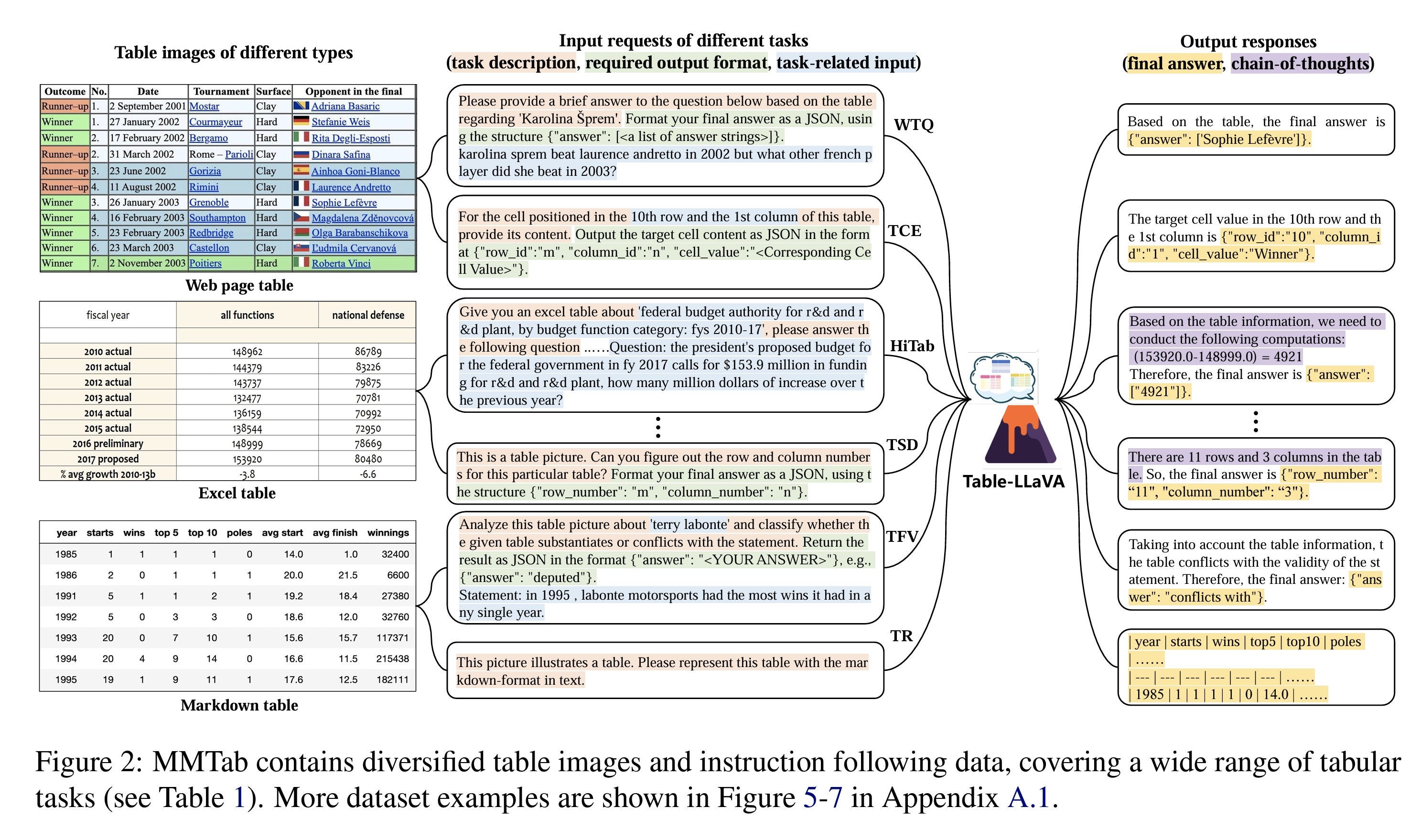
They initially show that most current multimodal LLMs, exception of GPT-4, perform poorly on this task according to various benchmarks. Subsequently, they combined 14 different datasets to create a comprehensive dataset for pre-training and fine-tuning a LlaVA model. This was achieved using a table rendering script that converts Webpage, Excel, or markdown tables into diversely formatted images for input into the LLM. The pre-training step aims to teach the model to generate text (e.g., HTML) from an image of a table.
The pre-training phase instructs the model on the general structure of a table. The second step uses a format such as <table image, input request, output response> to enhance the model's ability to answer specific questions based on an image of a table. They used a 7B (and 13B) LLaVA model featuring a ViT image encoder and the Vicuna LLM.
The results demonstrated that TableLLaVA significantly outperforms other methods and remains competitive with GPT-4V across multiple benchmarks.
Final Words,
What do you think of this newsletter? I would like to hear your feedback.
What parts were interesting? What sections did you not like? What was missing, and do you want to see more of it in future?
Please reach out to me at nlpiation@gmail.com.