

NLPiation #23 - Scaling Up Smarter
Advancing Language Models through Efficient Training and Alignment Techniques.

Welcome to my natural language processing newsletter, where I keep you up-to-date on the latest research papers, practical applications, and useful libraries. I aim to provide valuable insights and resources to help you stay informed and enhance your NLP skills. Let’s get to it!
Multi-Token Prediction
📝 Better & Faster Large Language Models via Multi-token Prediction [paper]
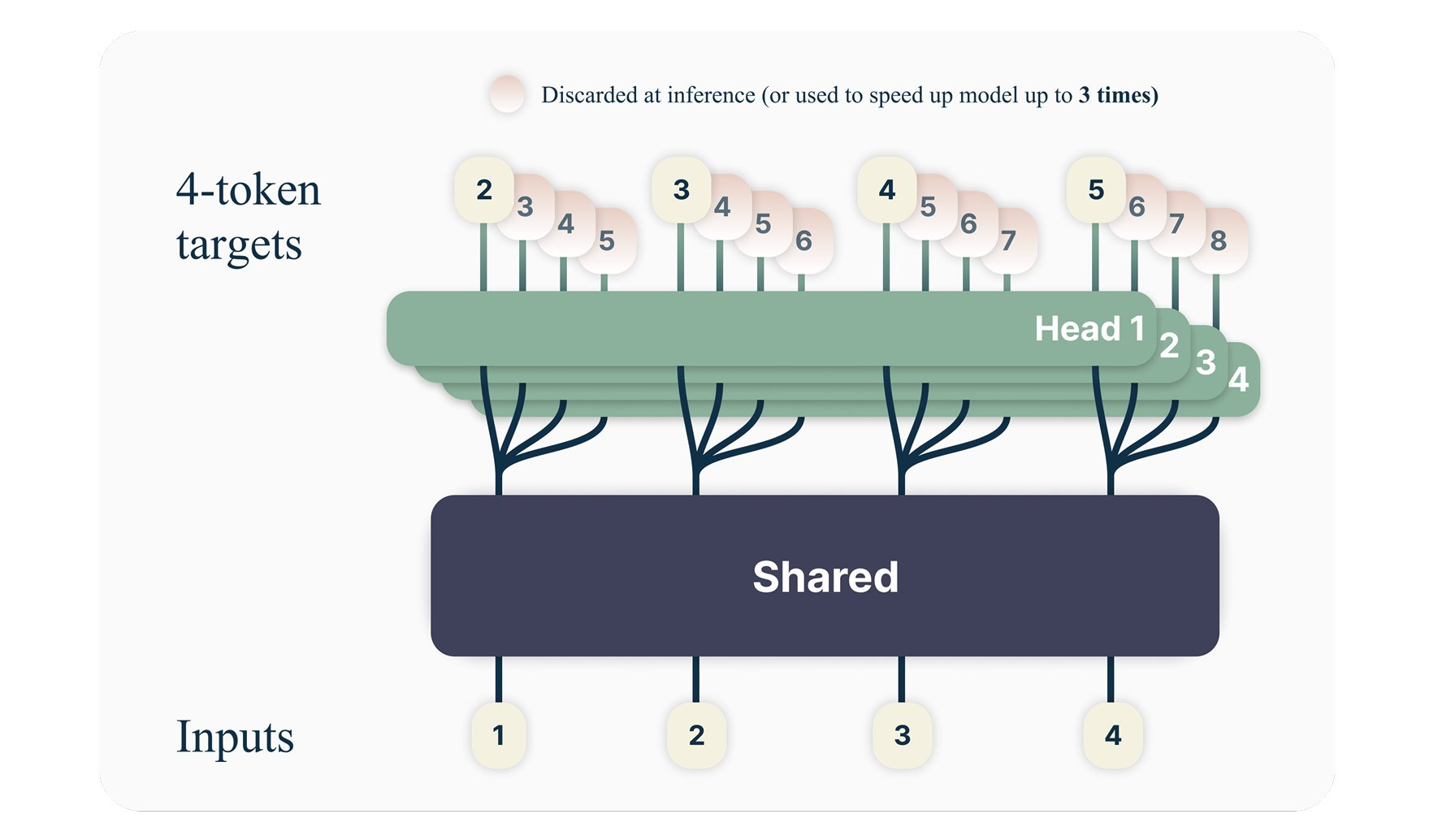
This paper proposes an approach where multiple tokens are predicted using multiple heads, shifting from the conventional method of predicting only the next token. The method uses a shared model (called trunk) containing 13 billion parameters. During training, tokens are processed individually, with their losses computed and aggregated before the backward pass and weight updates are done. This ensures that memory usage will not grow.
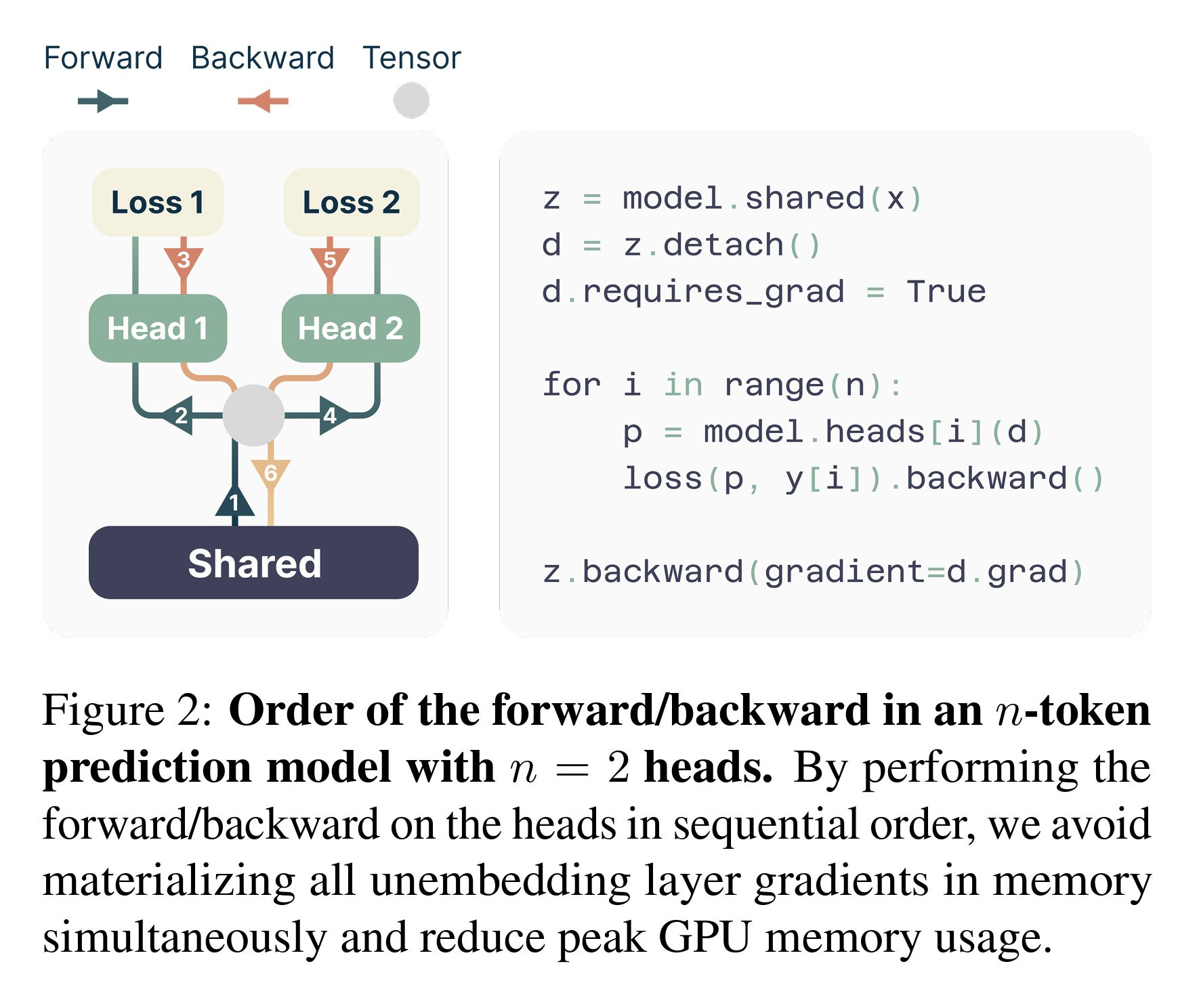
During the inference phase, the model can generate output tokens sequentially as previously done or leverage the proposed method to accelerate the inference process by a factor of three.
This method proved most effective on coding benchmarks like HumanEval and MBPP. Their thorough analysis indicates that the effectiveness of this method becomes more apparent as the scale increases. Moreover, experimenting with various numbers of heads revealed that predicting four tokens in advance yielded the greatest result improvement. They demonstrated a 12% enhancement in HumanEval and a 17% increase in problem-solving rates on MBPP. Although they applied the approach to tasks like Q&A and summarization, it didn't boost performance but can significantly speed up inference processing.
Other researchers have explored multi-token prediction techniques; this paper stands out for its innovative approach and comprehensive model analysis, making it a great read. However, it would have been nice if they had released the code too.
Extended LSTM
📝 xLSTM: Extended Long Short-Term Memory [paper]
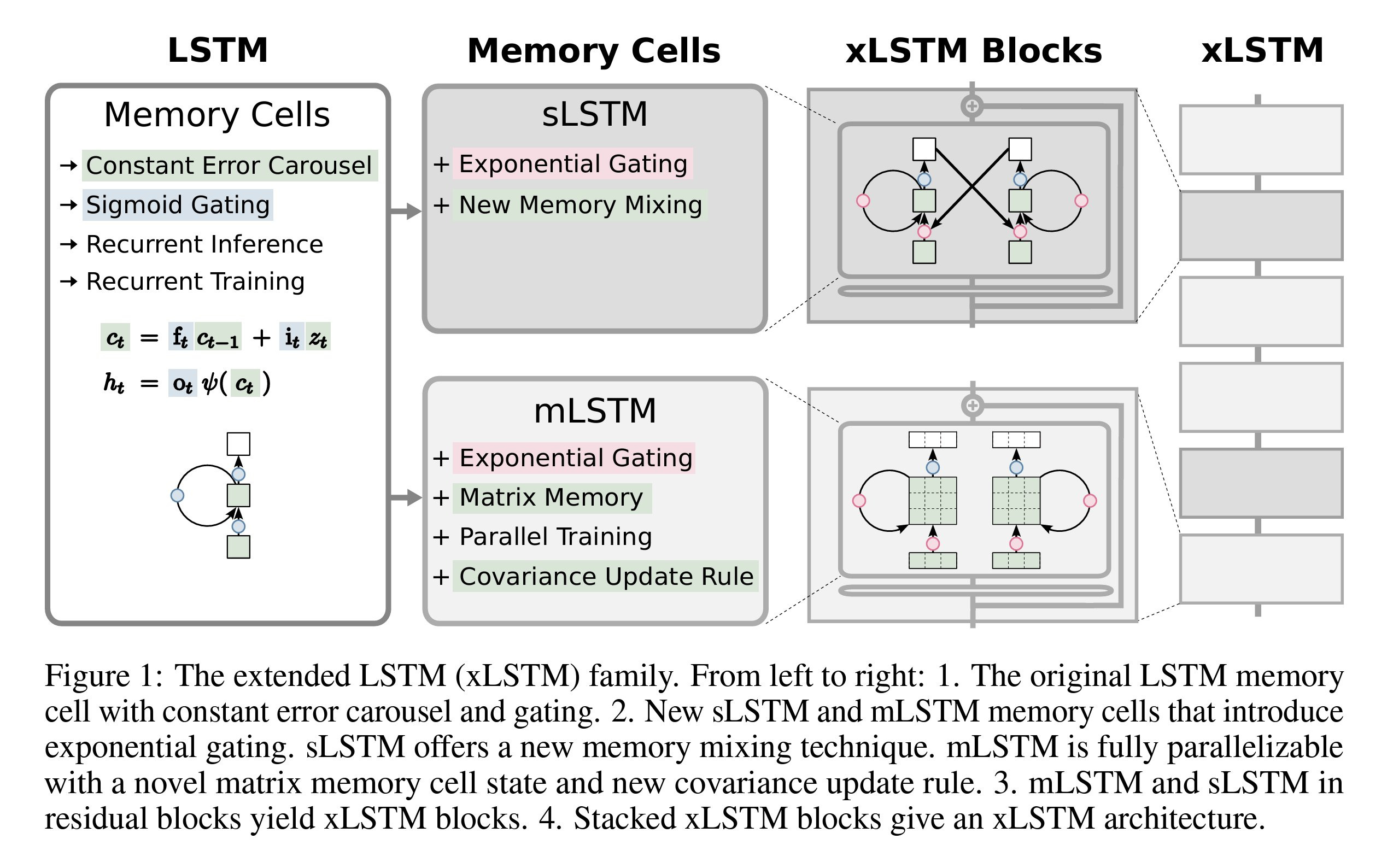
The author of LSTM released the idea of xLSTM to overcome the limitations of the original architecture. One of the important aspects was the lack of parallelization, which slowed the network during training/inference. The two novelties of this paper are the use of exponential gating (instead of Sigmoid) and the replacement of scalar memory with Matrix memory. These ideas, amongst others, led to the creation of the sLSTM and mLSTM memory cells. Stacking the two mentioned components with a residual connection forms an xLSTM component, and multiple xLSTM components can be layered to create the xLSTM architecture.
The resulting model has parallel processing capabilities during both training and inference. The network benefits from increased memory capacity and enhanced memory updating efficiency. Notably, it incorporates an attention-like mechanism using key/value/query vectors within its components. The model achieves faster performance and uses fewer computational resources than the transformer architecture while slightly outperforming or matching transformer-based models in text generation and classification.
Unlike what I thought when I saw this paper, It's more like a transformer network rather than a traditional LSTM. The only common element in the new architecture is the idea of gated design!
DPO vs PPO
📝 Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study [paper]
Since the release of the DPO paper, there's been a lot of buzz about whether the DPO approach, which is notably simpler than PPO, performs at the same level. Companies like OpenAI use Reinforcement Learning (RL) to train models such as ChatGPT, whereas many open-source/academic projects do DPO. The advantage of not needing to train a reward model is that it is more feasible to train models with fewer resources and fewer trials.
Experiments were conducted to evaluate the performance of LLMs tuned with DPO and PPO. The models were tested on the HH-RLHF dialogue task and two coding tasks. The results demonstrated that PPO consistently improves the model's performance on complex tasks such as coding. They also discovered that using iterative DPO, which involves generating additional data with the newly trained rewards model during the tuning process, is more effective. However, PPO still outperforms DPO and achieves state-of-the-art results on challenging coding tasks.
Lastly, the ablation study highlights the crucial elements for the success of PPO training: normalizing advantages, using large batch sizes, and updating the reference model parameters with an exponential moving average.
No Attention?
📝 Pretraining Without Attention [paper]
The idea is to explore if we can match the performance of the transformer-based models without an attention mechanism. They propose an architecture based on the combination of State-Space models (SSMs) and multiplicative gating.
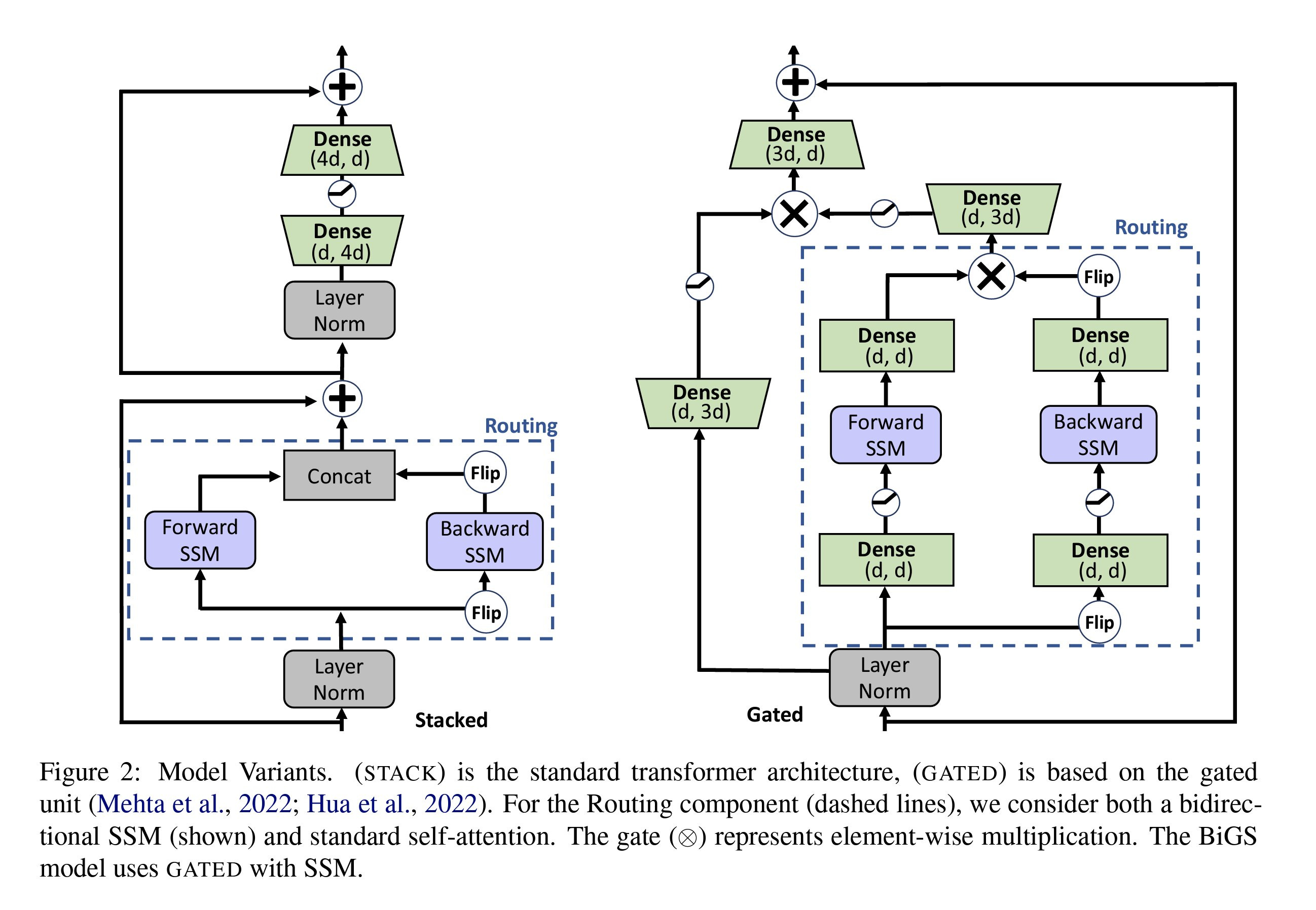
They replaced the attention-based routing with the State-Space models. (High-level overview coming... details not necessary for now!) These models describe a system's behaviour by linking unobservable variables to controllable inputs and measurable outputs. The model offers a method to achieve long-range dependencies similar to RNNs with the training speed of CNNs. Interestingly, they achieved comparable accuracy to BERT on the GLUE benchmark by simply matching the number of parameters!
The BiGS model does not exhibit quadratic complexity in relation to the length seen in transformers; instead, its complexity is linear at 2L. The paper suggests that this model may be the first to rival transformers without using attention. This fascinating research indicates that the transformer architecture isn't inherently unique or special. There may be other architectures using the same components but arranged differently that perform similarly yet more efficiently.
Maybe we should focus on finding different architectures and techniques at the same time that we are scaling the transformer to jizilion parameters :)
Final Words,
What do you think of this newsletter? I would like to hear your feedback.
What parts were interesting? What sections did you not like? What was missing, and do you want to see more of it in future?
Please reach out to me at nlpiation@gmail.com.