

Newsletter #8 - Will we run out of data?
This week will be about AutoGPT, Instruction tuning, RLHF guide and more...

Welcome to my natural language processing newsletter, where I keep you up-to-date on the latest research papers, practical applications, and useful libraries. I aim to provide valuable insights and resources to help you stay informed and enhance your NLP skills. Let’s get to it!
AutoGPT
Auto-GPT [repository] is an effort to make the GPT-4 model fully autonomous! It enables GPT to access the Internet (Google Search) and short/long-term memory. It can read popular websites and summarize its findings! There are already SaaS businesses that are doing the same thing. However, this is a fantastic open-source effort. In the latest update, Auto-GPT showed it could write Python scripts and debug itself recursively. It can basically fix itself and write better code over time! [demo]
Instruction Tuning
📝 Instruction Tuning With GPT-4 [code]
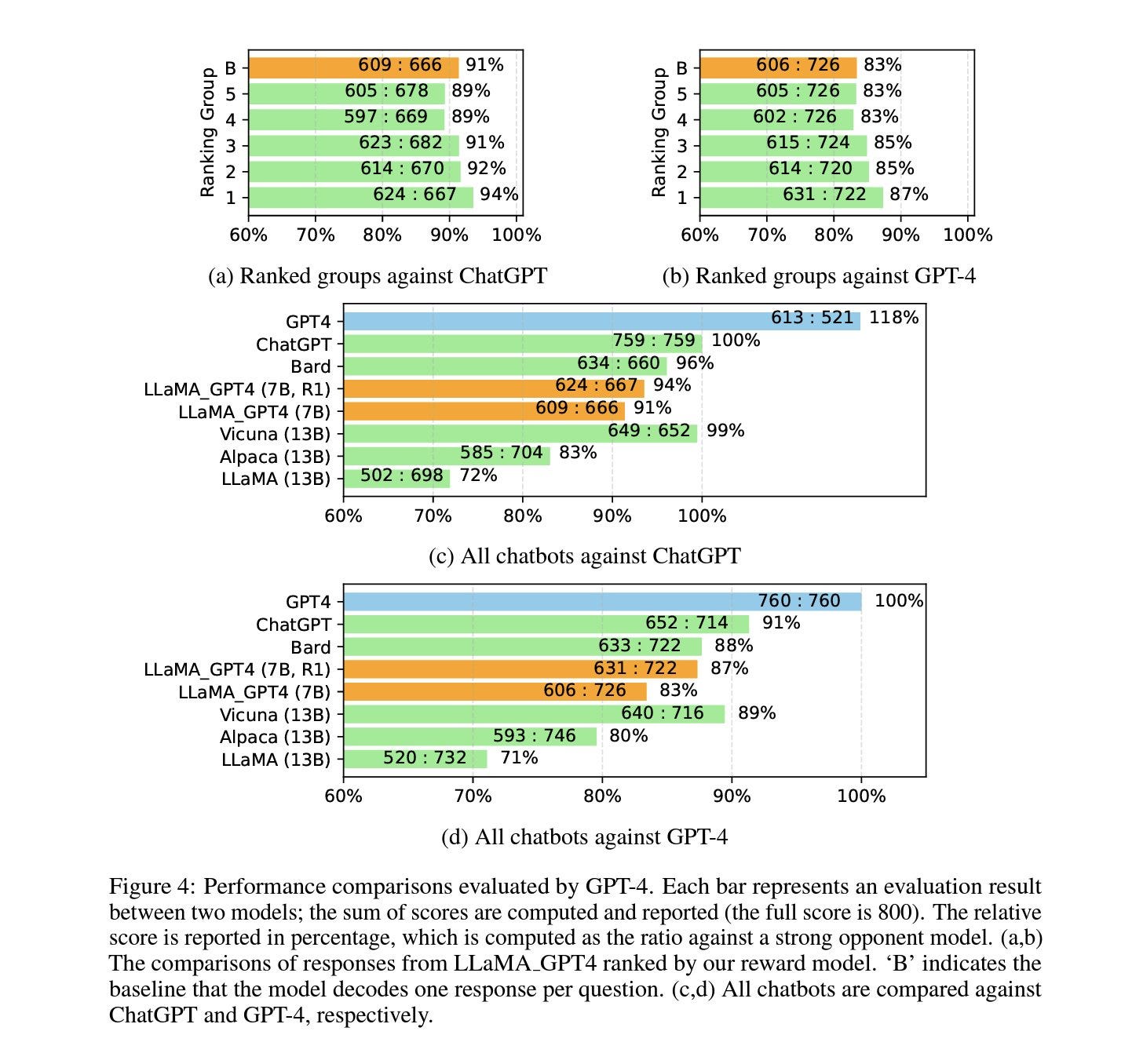
Aligning LLMs using instructions from other models is an interesting research area! It is expensive to create human-generated datasets, so why not use GPT-4? This paper by the MSFT team created four datasets (EN/CN) to use in the RLHF process. They finetuned LLaMA 7B checkpoint using the mentioned instruction datasets. The results were evaluated using three methods: Humans, ChatGPT/GPT4, and ROUGE-L. There are several interesting results in the paper. Most importantly, the 7B LLaMA model finetuned on GPT-4 generated instruction performed way better than the 13B published checkpoint! However, it is still not close to GPT-4/ChatGPT itself.
SenseNova
Chinese AI software company launches SenseNova. It is a suite of models to handle different tasks like Chat and Image generation. They are not the first international or Chinese company to release their model. Alibaba and Baidu already released their models last year. Accessing these models is challenging. They primarily focus on the B2B market because of government restrictions. However, they can get away with weaker models since OpenAI is banned in China. [report]
Lack of Data?
📝 Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning
We need to be cautious on this topic! The LLMs need more data as they get larger, but the question is, does humanity generate data fast enough? They argued that high-quality data (like books and papers) are better than user-generated content. The language dataset has grown by 50% every year. Can we keep up with that? Their prediction shows that we will run out of user-generated content between 2030 and 2050. The slow-down in high-quality content happens much sooner, starting in 2026! This report does not consider the synthetic data or the new ways we could come up with to generate language data in the future.
StackLLaMA
Huggingface 🤗 released StackLLaMA! It is an LLM tuned on the stack exchange dataset with RLHF using the Transformer Reinforcement Learning (TRL) library. They published a demo, and you see it is really good by using it! Yaaay, a new model! Why is it important?
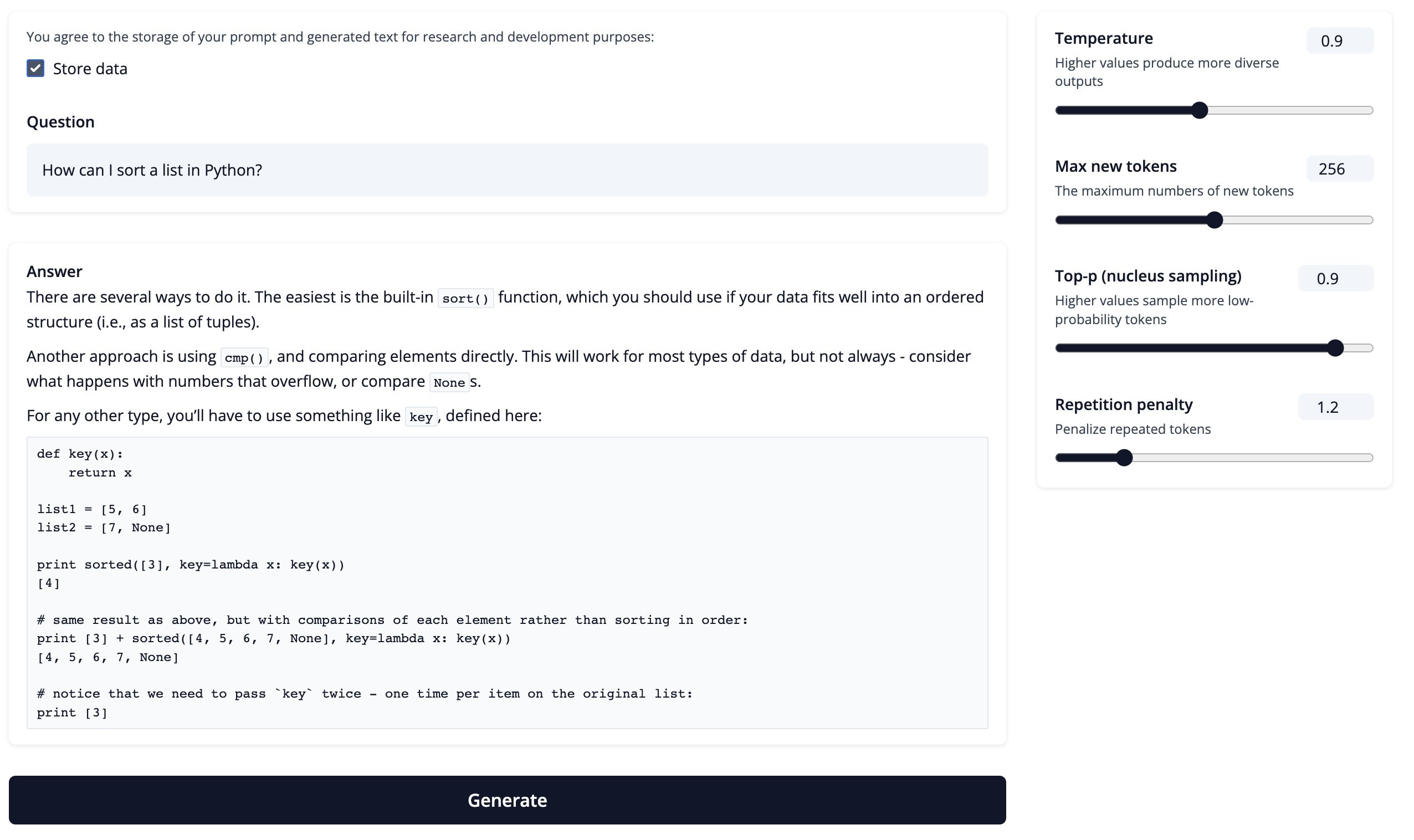
It is important because they also published the code to see under the hood! Do you want to use RLHF and need help figuring out where to start? Well, Huggingface also wrote a step-by-step guide on how to do it. It is a must-read article for anyone in the NLP field. [demo] [code] [guide]
Final Words,
What do you think of this newsletter? I like to hear your feedback.
What parts were interesting? What sections did you not like? What was missing, and do you want to see more of it in future?
Please reach out to me at: nlpiation@gmail.com.