

Newsletter #22 - Optimizing Model Merging, Code, and Labels
This month, we explore optimizing model merging, fine-tuning supervision, autonomous coding, and selective token relevance in NLP.

Welcome to my natural language processing newsletter, where I keep you up-to-date on the latest research papers, practical applications, and useful libraries. I aim to provide valuable insights and resources to help you stay informed and enhance your NLP skills. Let’s get to it!
Model Merging
📝 Evolutionary Optimization of Model Merging Recipes [paper] [code] [demonstration]
{kind=link}

Model merging has recently gained significant attention within the LLM community. The team at SakanaAI introduced an evolutionary approach that emphasizes both manipulating the parameters and the order of layers. The proposed approach, a hybrid of two methods, showed impressive performance on models fine-tuned from the same foundational pre-trained model. Moreover, their primary focus was cross-domain merging. We will see two examples of this at the end.
This method merges the parameter space (PS)—for example, by averaging the weights of two models—and the data flow space (DFS), which involves identifying the optimal sequence for mixing and matching the layers' order. They suggested a fusion of these two approaches. The PS procedure involves selecting various data points from the search space and iteratively seeking the optimal parameter combination. This method is an excellent alternative for issues that gradient computation cannot handle.
Also, DFS proposes the idea of repeatedly duplicating the model's layers in their original order. For instance, it means placing all the layers from model 1 first, then all the layers of model 2 on top, continuing this by going back to the layers of model 1, and so forth. Then, they optimize the model's efficiency by determining which layers should be eliminated and adjusting the weight of each layer's input to increase the model's performance. This approach limits the search space and has been validated through empirical studies.

Their findings demonstrated that combining a model fine-tuned for the Japanese language with another model containing mathematical capabilities can result in a model that excels at solving Japanese math questions, significantly outperforming the original models. Also, they experimented with merging a model with vision capabilities (VLM) but lacking Japanese culture comprehension with a fine-tuned Japanese LLM. This created a model capable of tackling complex visual question-answering tasks within the context of Japanese culture.

Classification with LLMs
📝 Label Supervised LLaMA Finetuning [paper]
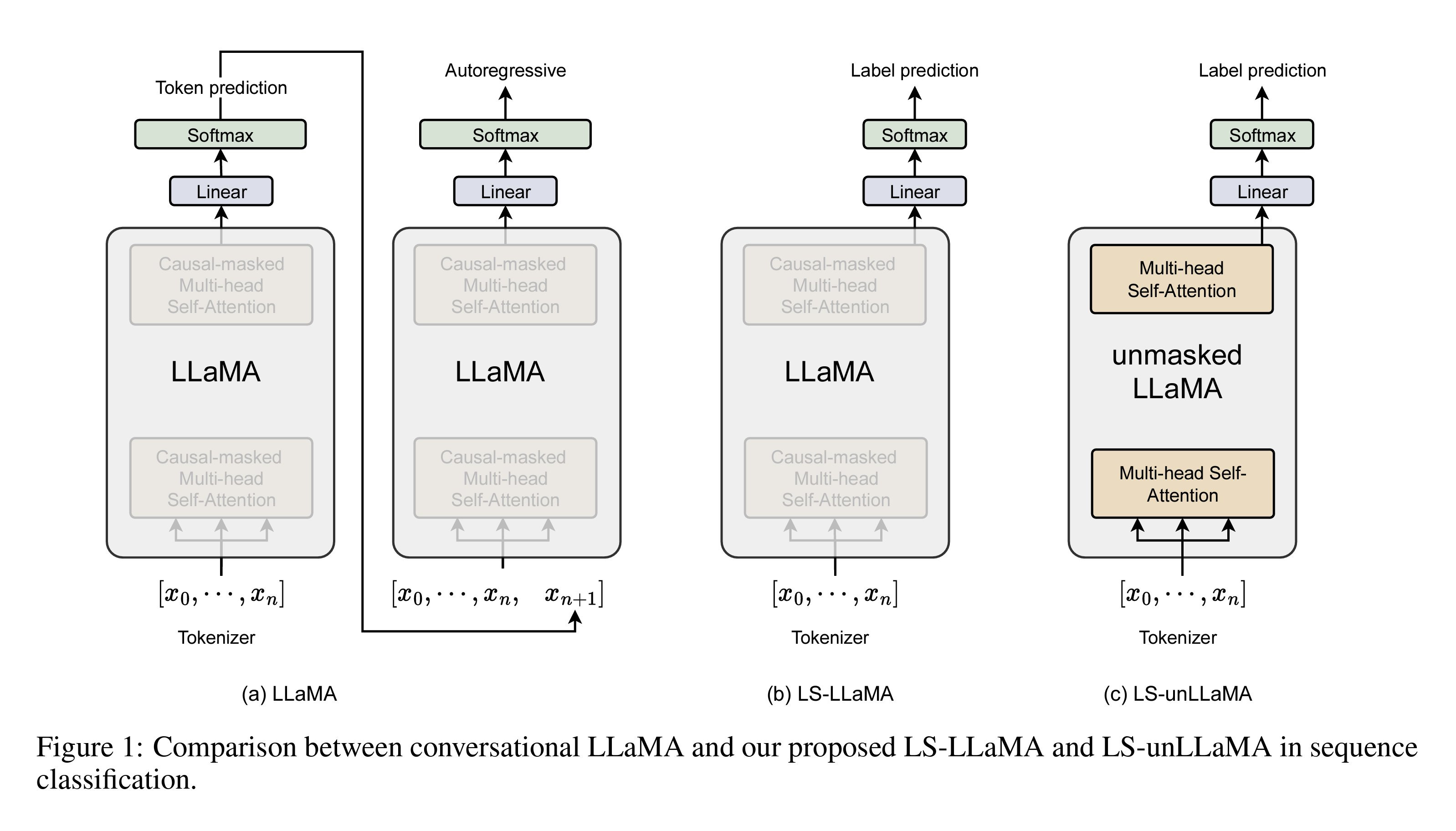
This paper explores the concept of performing classification tasks using the latent representations of an LLM (decoder-only model) rather than instructing the model to do classification through zero- or few-shot learning. The research shows that instruction tuning does not enhance performance for classification tasks, presenting evidence that models with 175 billion parameters, such as GPT-3, fail to surpass the performance of the RoBERTa large model.
Their approach applies the strategy used in encoder-only models like BERT, to fine-tune a decoder-only model, resulting in two proposed methods. The first one involves using the final layer representation of LLaMA to predict the label rather than the next token. (LS-LLaMA) Secondly, removing the masking mechanism of the decoder enables it to access all tokens while generating representations. Typically, masked self-attention restricts attention to previous tokens at each step, which hurts the model's understanding of the text. (LS-unLLaMA)
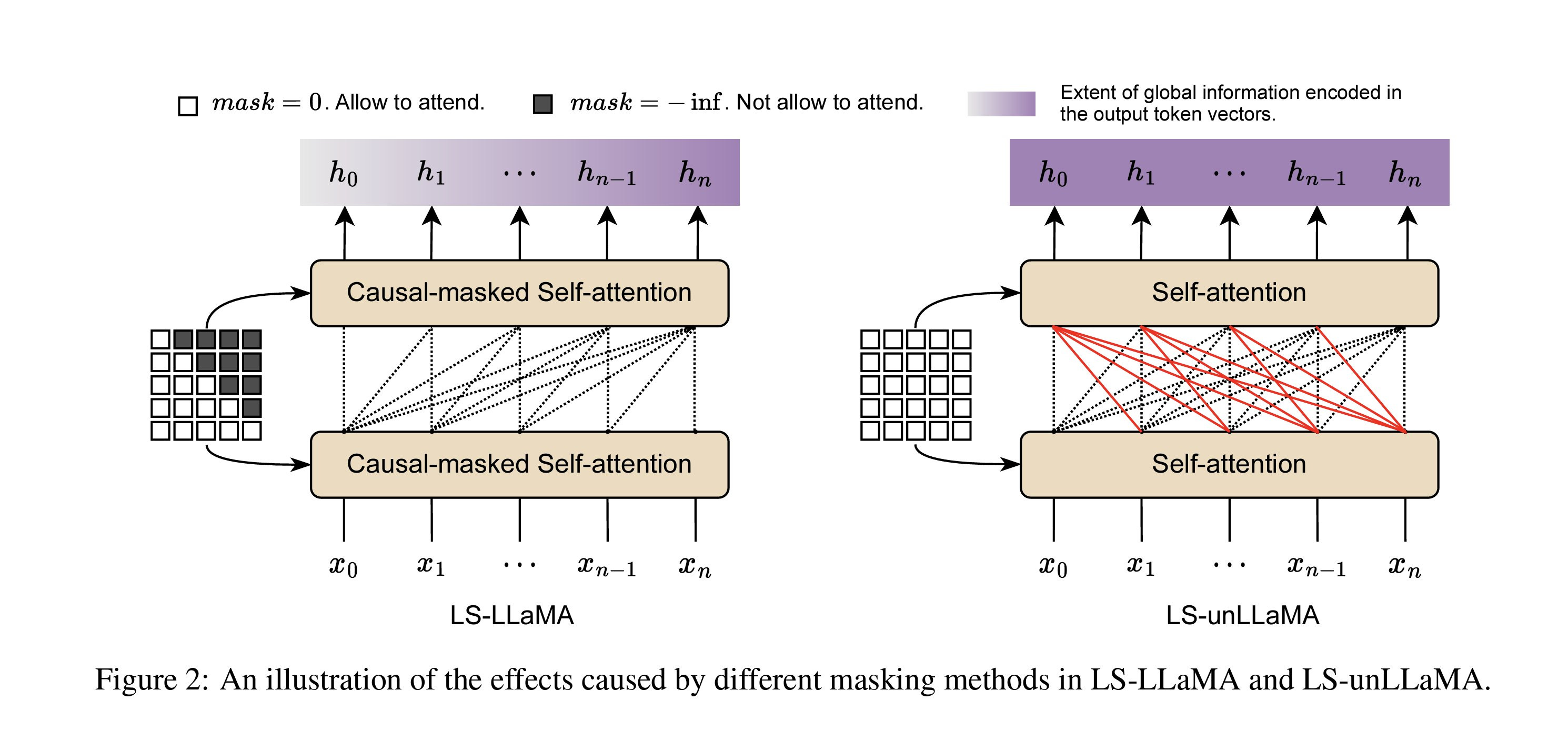
They conducted fine-tuning experiments using LLaMA-7B and LoRA for tasks such as Multiclass/Multilingual classification and Named Entity Recognition (NER). The findings suggest that the LS-unLLaMA model outperforms in all experiments. The correlation between model size and performance is a fascinating research area for me, and this paper presents intriguing but expected results! However, a significant missing angle in this research is comparing performance gains relative to older and smaller models.
This study achieved a 1.26% increase in accuracy over RoBERTa Large (355M) using a model with 7B parameters. While LoRA enhances the efficiency of the fine-tuning process, it's important to note that this model is 20 times larger and requires substantially more resources.

It is crucial to consider the benefits of LLMs not only in terms of performance but also in terms of accessibility and energy consumption, especially when a much smaller model might be as capable for the task.
Autonomous Coding
📝 AutoCodeRover: Autonomous Program Improvement [paper] [code]
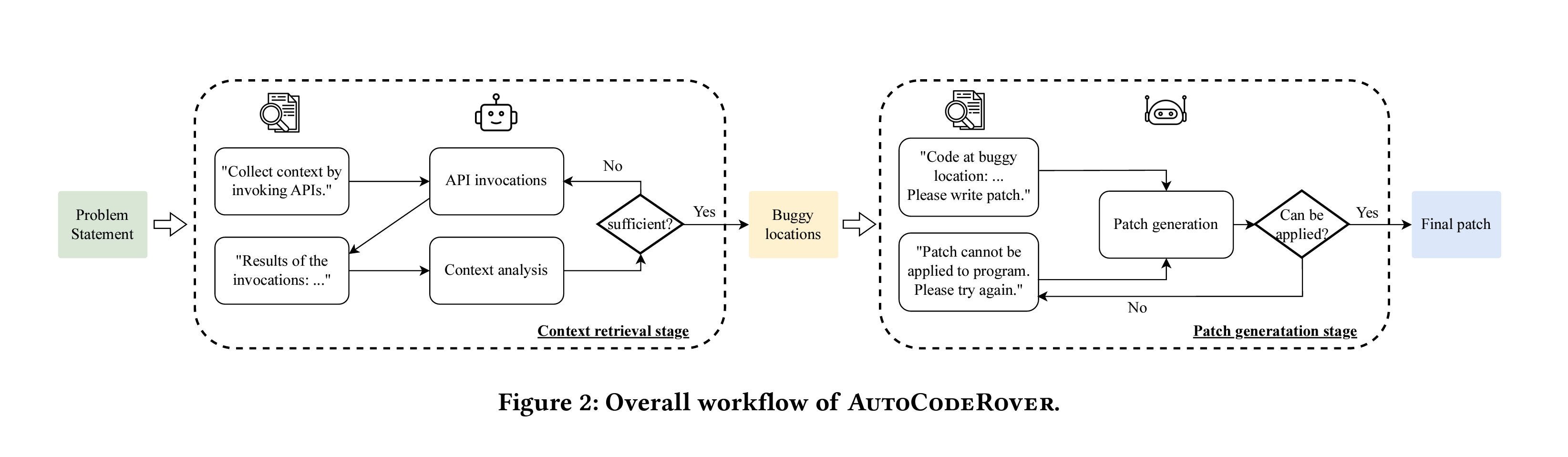
The researchers at the National University of Singapore presented the AutoCodeRover agent, which can be used to execute bug fixes and feature additions without human intervention. This process involves two main steps. First, the agent identifies the bug's location by providing access to the repository and the issue description. Then, the agent writes patches to correct the bug, ensuring the new code runs without syntax errors.
The paper uses test sets to enhance agent performance through the spectrum-based fault localization (SBFL) method. This method helps identify faulty components by prioritizing investigation into components frequently causing errors, considering them more suspicious. Additionally, using test cases will help the agent validate its approach, ensuring it corrects syntax errors and truly resolves the issue.
Does this sound familiar? Indeed, it's pretty similar to the infamous Devin!
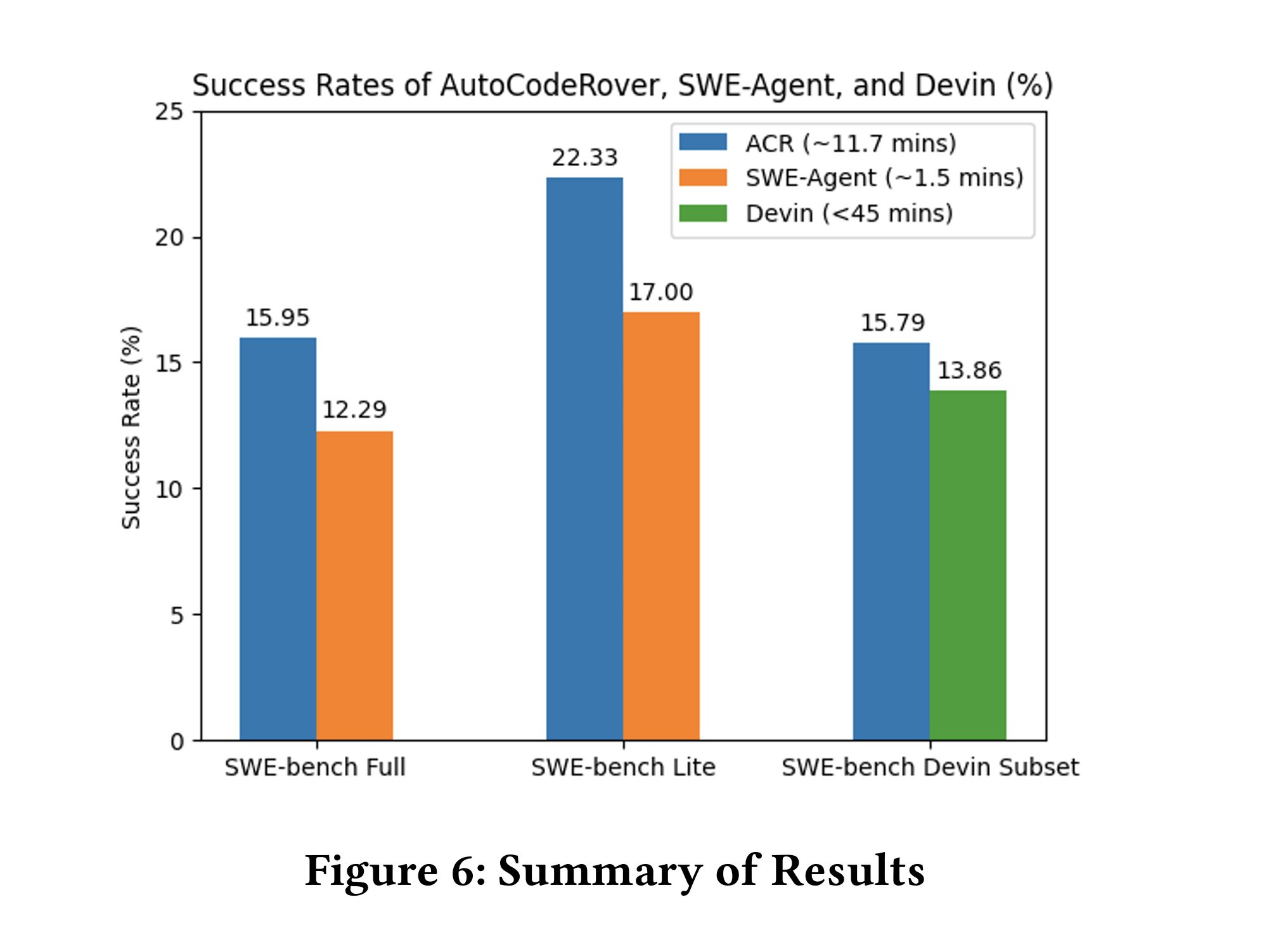
And, it has proven to be more effective than Devin in solving the SWE benchmark, achieving a 16% success rate in fixing issues. Additionally, it completes the task more quickly, taking only 1.5 minutes compared to Devin's 45 minutes.
Token Importance
📝 Rho-1: Not All Tokens Are What You Need [code]
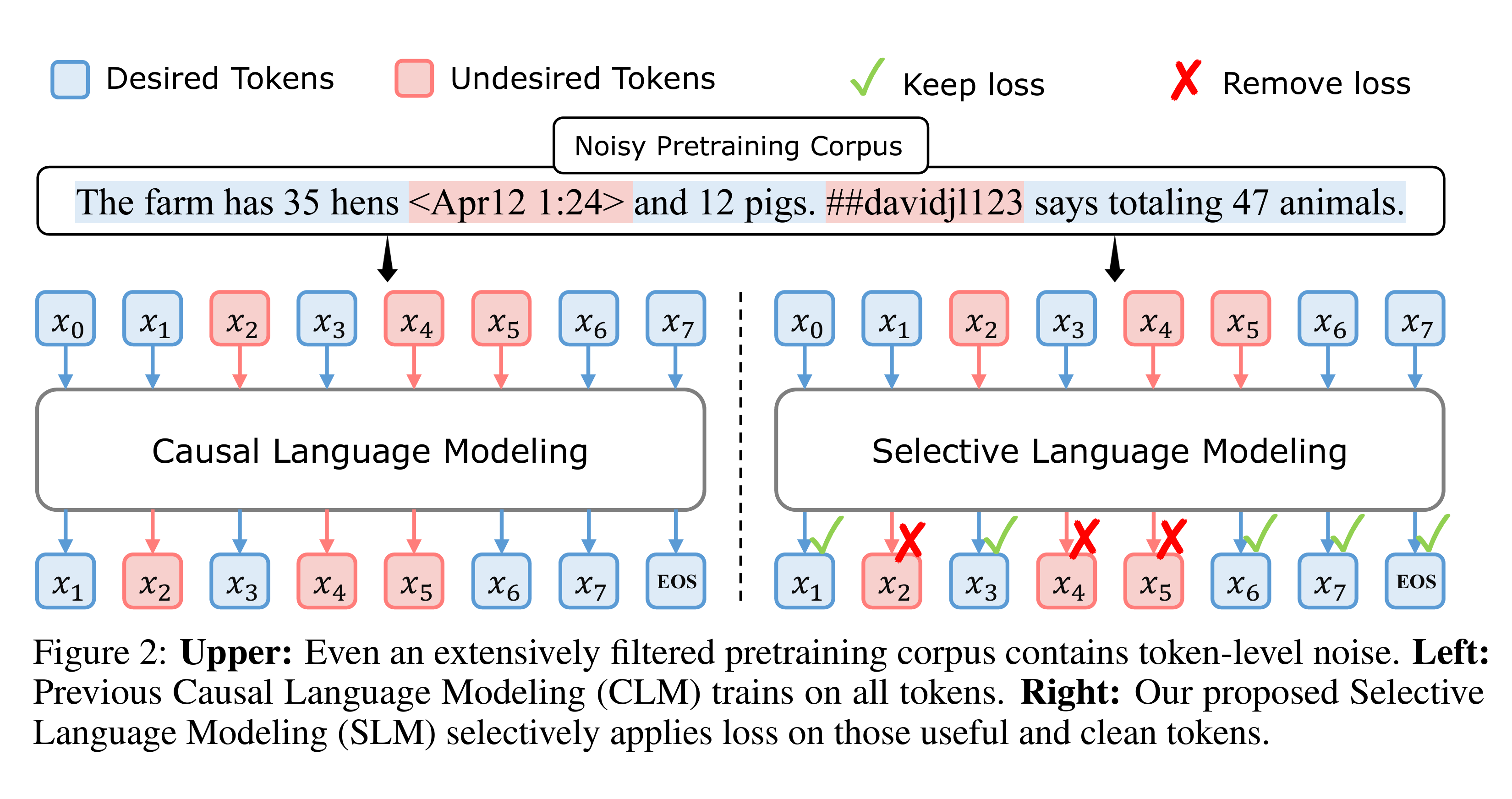
The dominant pre-training objective for LLMs is the next token prediction, where the model is trained on all the tokens in the dataset. This paper argues that not all the tokens in the dataset have equal importance. They observed that token loss doesn’t consistently decline, unlike overall loss. Specific tokens consistently exhibit either high or low loss values. Or, in numerous instances, tokens' loss fluctuates during training, suggesting the model struggles to learn them.
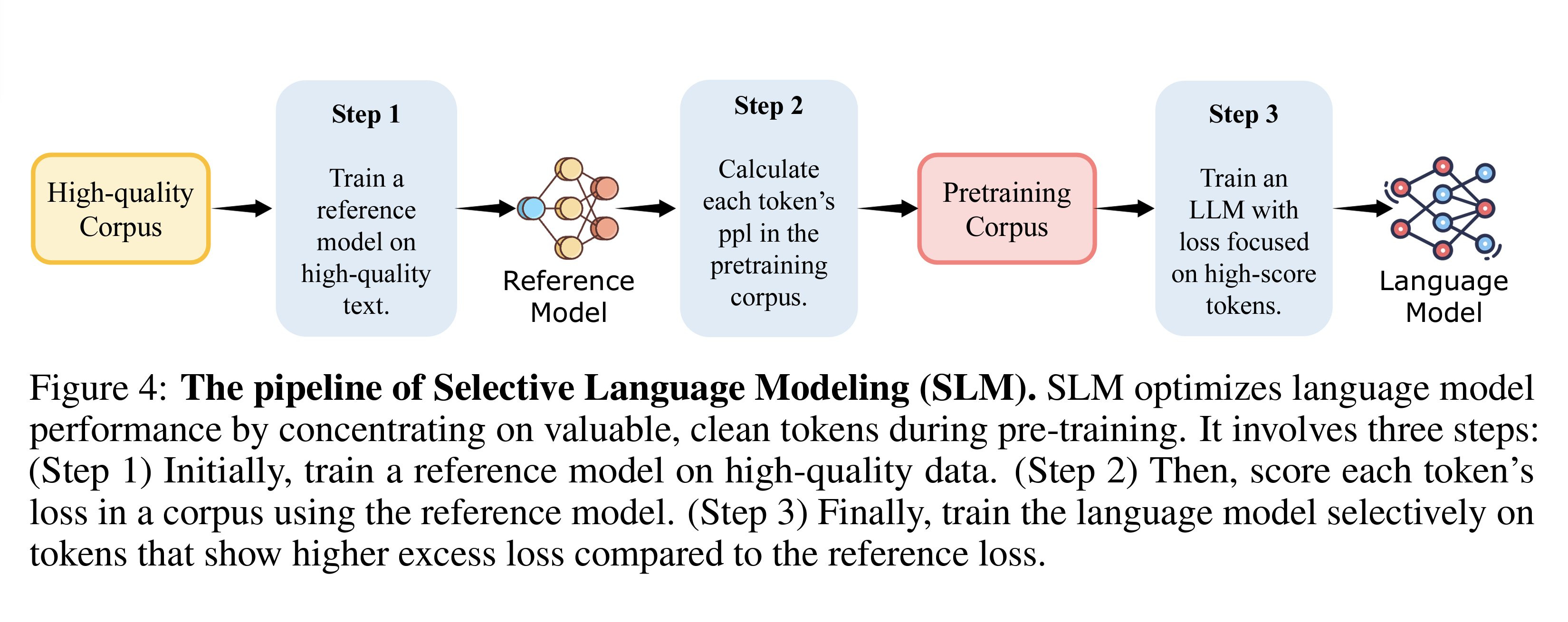
The idea is that hard tokens often represent noisy information, and filtering them during training can lead to better convergence. This resulted in Selective Language Modeling (SLM), which essentially removes certain tokens during training. (as shown in the image) The proposed approach is to train a reference model on high-quality data and use it to assign scores (perplexity) to each token in the pre-training dataset. Lastly, they pre-trained a language model on the high-scored tokens.
They incorporated this method to train a model on the math question datasets. Their approach was able to improve the performance on few-shot learning by 30% and state-of-the-art results after fine-tuning.
These findings are logical, as we are training the model to concentrate on tokens that are more relevant to a specific task. (kind of like a task-specific model) Still, it is intriguing that removing some tokens from the corpora could lead to performance improvements.
Final Words,
What do you think of this newsletter? I would like to hear your feedback.
What parts were interesting? What sections did you not like? What was missing, and do you want to see more of it in future?
Please reach out to me at nlpiation@gmail.com.