

Newsletter #21 - Synthesizing, Simulating, Stealing
Crafting synthetic datasets, questioning embedding similarities, simulating learning processes in language models, and addressing security concerns in NLP systems.

Welcome to my natural language processing newsletter, where I keep you up-to-date on the latest research papers, practical applications, and useful libraries. I aim to provide valuable insights and resources to help you stay informed and enhance your NLP skills. Let’s get to it!
Cosine-Similarity
📝 Is Cosine-Similarity of Embeddings Really About Similarity? [paper]
Cosine similarity is the go-to method for retrieving similar documents in RAG (Retrieval-Augmented Generation) pipelines. This study performs a series of experiments to evaluate the effectiveness of this metric. Their findings indicate that cosine similarity can yield random outcomes in linear models, depending on the applied normalization or regulation methods. They suggest it shouldn't be used blindly in all circumstances since the results are inconsistent.
Unfortunately, they didn't offer alternative methods. But, we can look at the recommendations from the model providers since they set the learning objective and the normalization methods. Like OpenAI, which recommends using cosine similarity in their embedding models.

Synthethic Instruction Tuning
📝 Synthetic Data (Almost) from Scratch: Generalized Instruction Tuning for Language Models [paper]
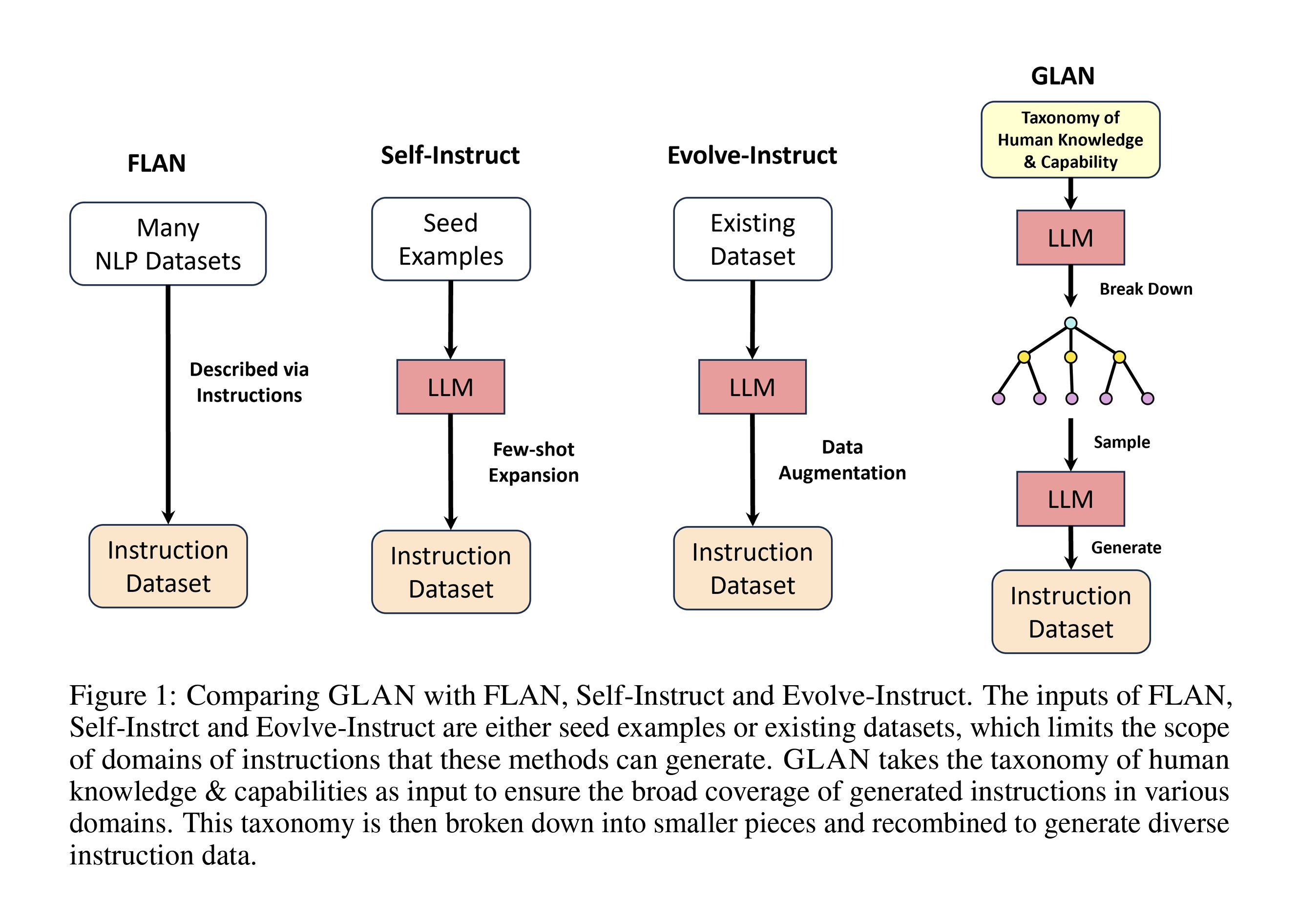
This paper introduces GLAN, an approach for creating an instruction-tuning dataset by leveraging a previously established taxonomy of human knowledge and capabilities as input. unlike methods that build the dataset from existing datasets or few-shot examples, GLAN uses a pre-curated syllabus covering various subjects. First, GPT-4 is used to compile a list of all human knowledge and capabilities, which is then refined by human evaluators.
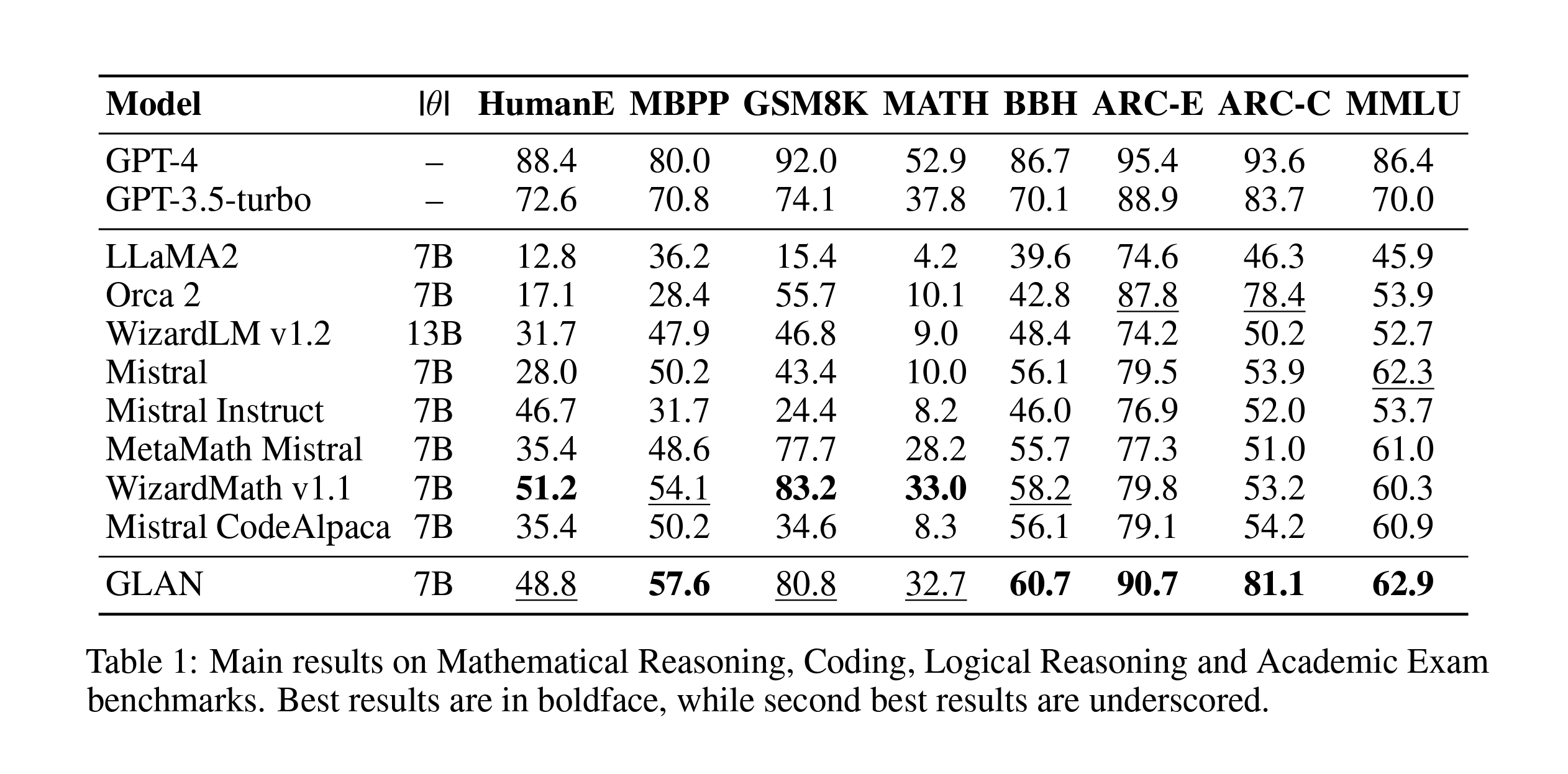
Next, they used the mentioned list to create subjects for each item along with a course syllabus, drawing inspiration from the educational system's structure. Finally, the course materials are used to generate homework assignments that can be used in the tuning process. They fine-tuned the Mistral-7b model, and the results showed that it either matched or exceeded performance across eight benchmarks. In contrast, other models might excel in a specific task, such as coding, but fall short in others, like academic exams.
Using Tools
📝 LLMs in the Imaginarium: Tool Learning through Simulated Trial and Error [paper] [code]
This study explores a less examined aspect of using tools in LLMs, demonstrating that well-known models, such as GPT-4, or open-source variants, achieve accuracy levels ranging from 30% to 60%. Not reliable at all!
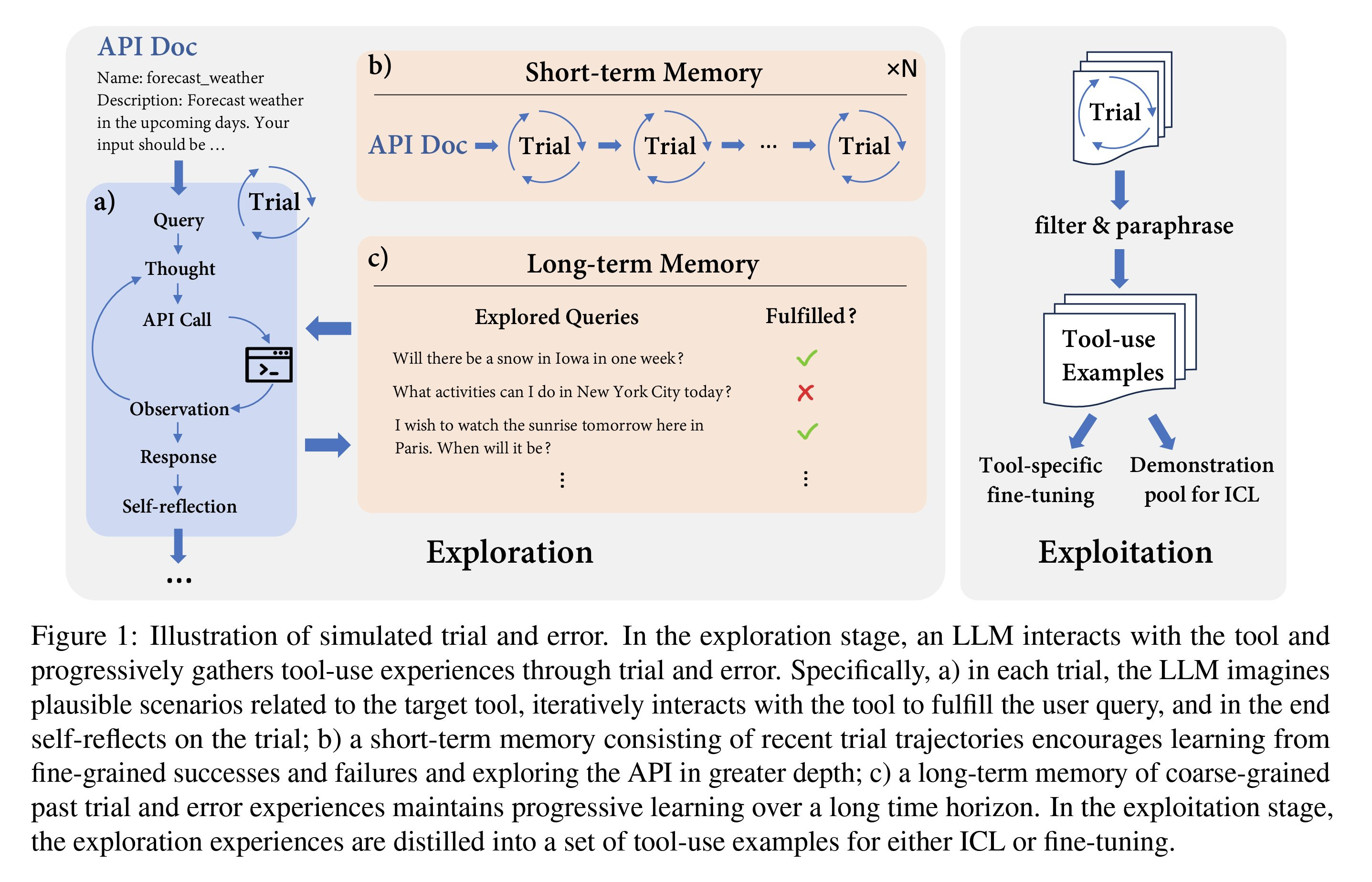
The paper suggests a three-step biologically inspired method. First, through trial and error, the model interacts with the tool/APIs and learns from these interactions, mimicking the human behaviour of experiencing and not only depending on manuals. Second is the thought phase, where the model imagines plausible scenarios for using the tool. The LLM will iteratively try to fulfill the mentioned scenarios and learn from feedback. Lastly, long- and short-term memories are used to keep track of the findings.
They establish episodes for each tool and a series of trials to learn interaction with the specified tool. As shown in the image, the trials use an internal short-term memory, whereas long-term memory is employed at the beginning of an episode for LLM's reference. The responses and long-term memory from these interactions can be used to fine-tune or as in-context learning (ICL) to augment interaction with models such as GPT-4. Both these approaches show to dramatically increase the accuracy of tool usage in LLMs.

This technique shows a 30.2% improvement using ICL with open-source models and a 46.7% boost in performance by fine-tuning the Mistral-Instruc-7b model.
Security
📝 Stealing Part of a Production Language Model [paper]
This study introduces a method for stealing details of proprietary black-box LLMs like OpenAI and Google's Palm-2. The vulnerabilities identified by this research have been patched as they reached out to these services. The method only works on services/APIs that return the logits of the generated response as well, and it can find the model's hidden dimension. The idea is to send randomly generated prompts to the model and use the SVD algorithm to find the matrix's rank.
The details of the mathematical proof are available on the paper, but the idea is that with a high enough number of prompts, it is possible to find the dimension with high confidence. Unfortunately, they haven't released the final findings, so the details of these models remain secret. However, they contacted researchers from both OpenAI and Google to confirm their findings and deleted the results/evidence.
Final Words,
What do you think of this newsletter? I would like to hear your feedback.
What parts were interesting? What sections did you not like? What was missing, and do you want to see more of it in future?
Please reach out to me at nlpiation@gmail.com.